
AWS Machine Learning Blog
Enhance agentic workflows with enterprise search u...
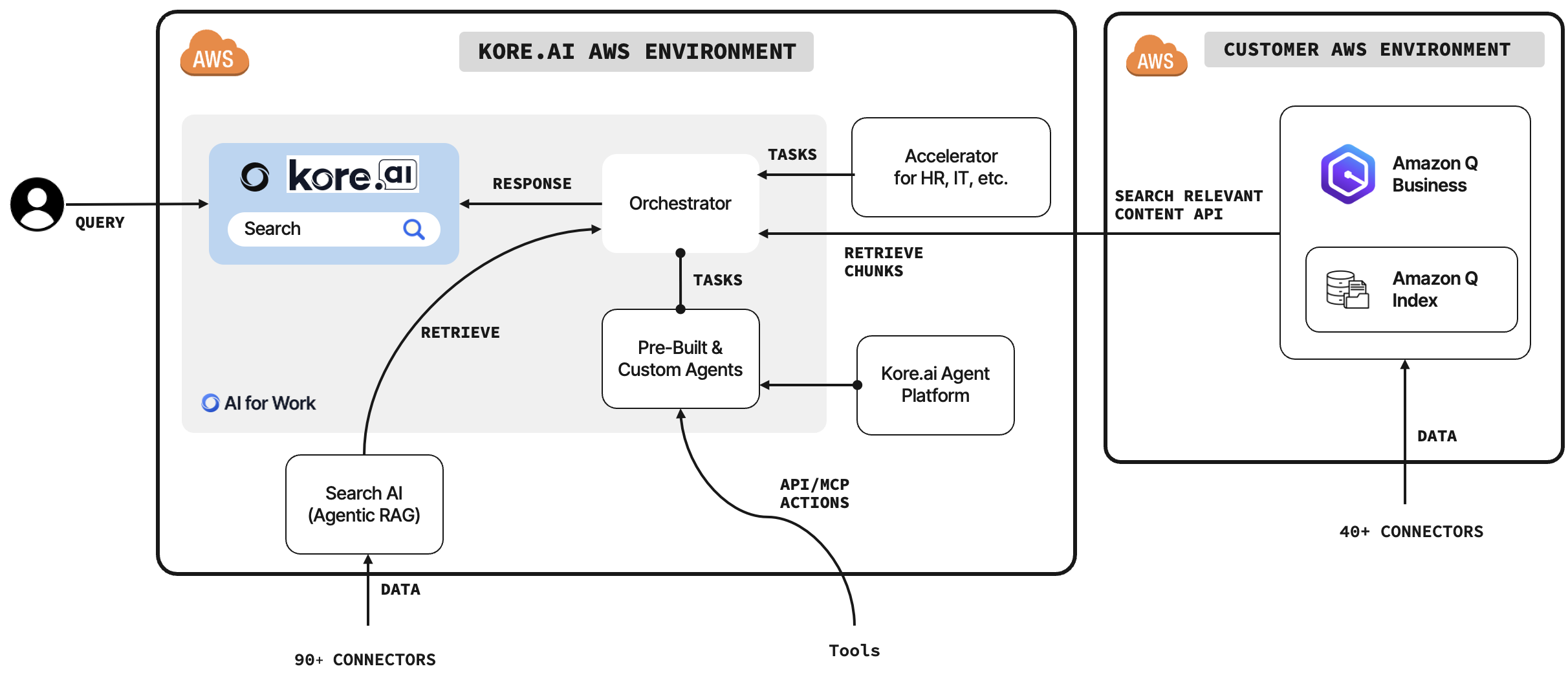
In this post, we demonstrate how organizations can enhance their employee productivity by integrating Kore.ai’s AI for Work platform with Amazon Q Business. We show how to configure AI for Work as a data accessor for Amazon Q index...
 8 hours ago
0
8 hours ago
0
Accelerate development with the Amazon Bedrock Age...
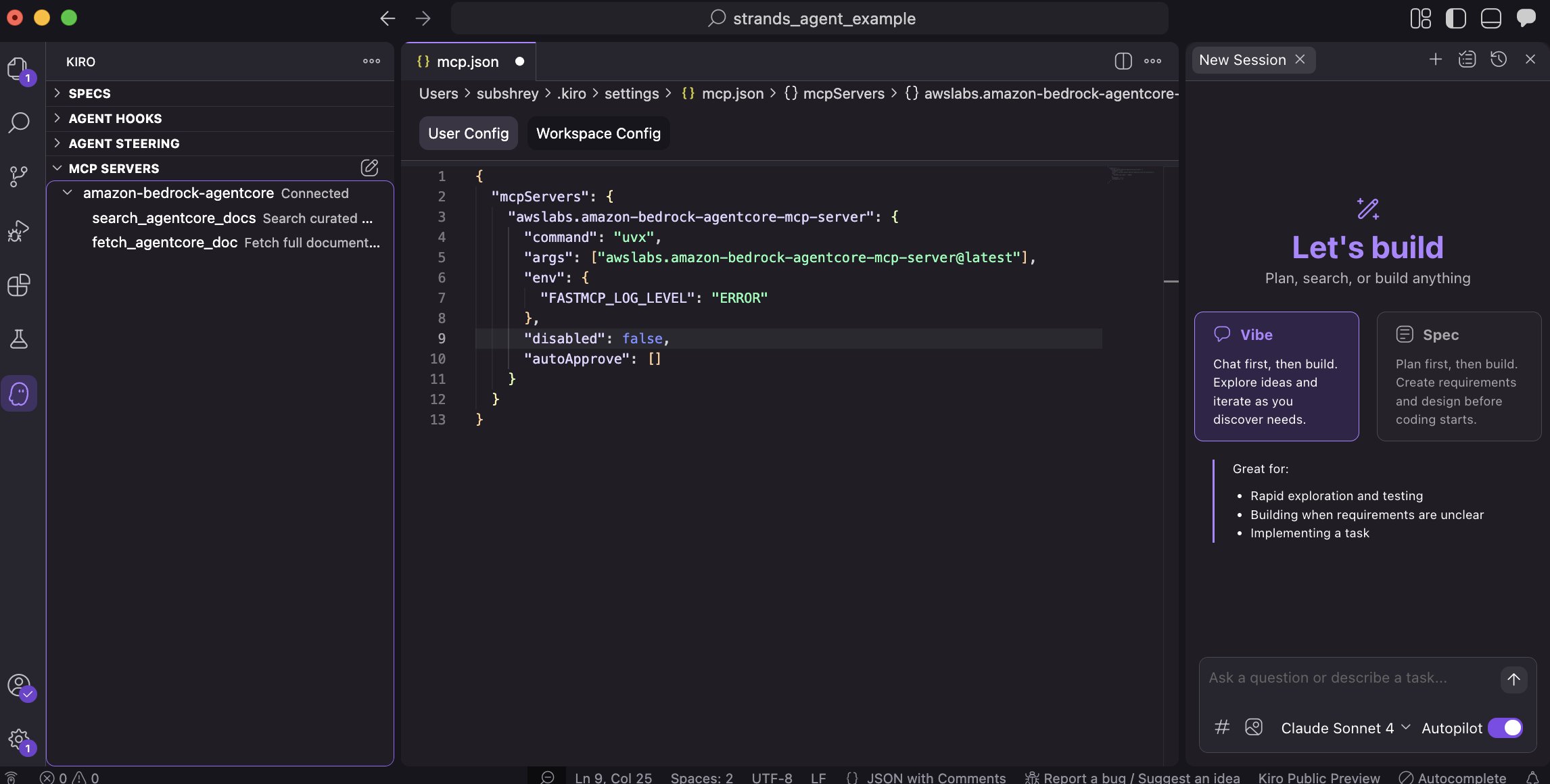
Today, we’re excited to announce the Amazon Bedrock AgentCore Model Context Protocol (MCP) Server. With built-in support for runtime, gateway integration, identity management, and agent memory, the AgentCore MCP Server is purpose-built to speed up creation of components compatible...
9 hours ago
0
How Hapag-Lloyd improved schedule reliability with...
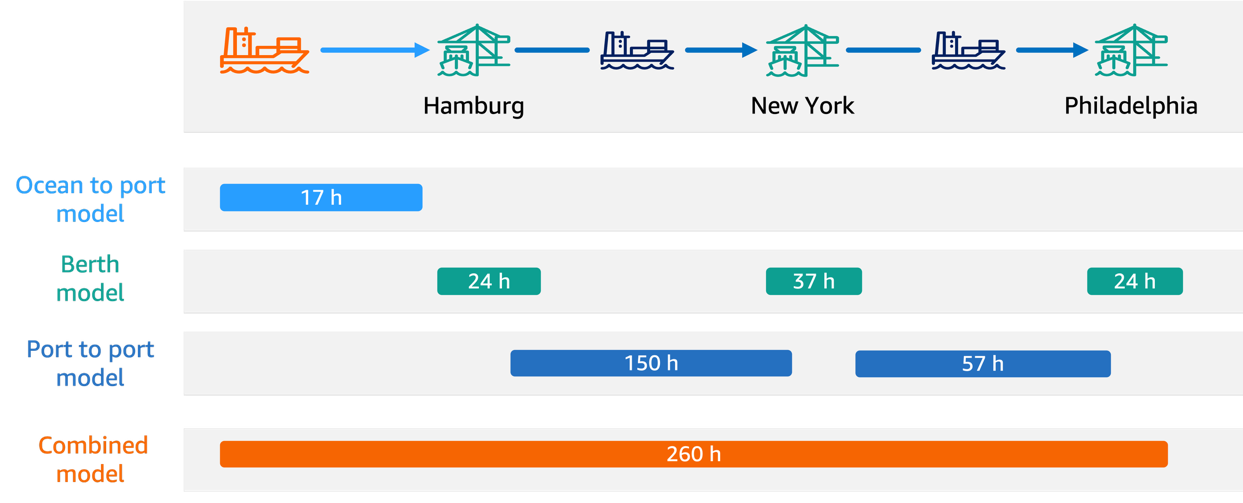
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced...
1 day ago
0
Rox accelerates sales productivity with AI agents ...
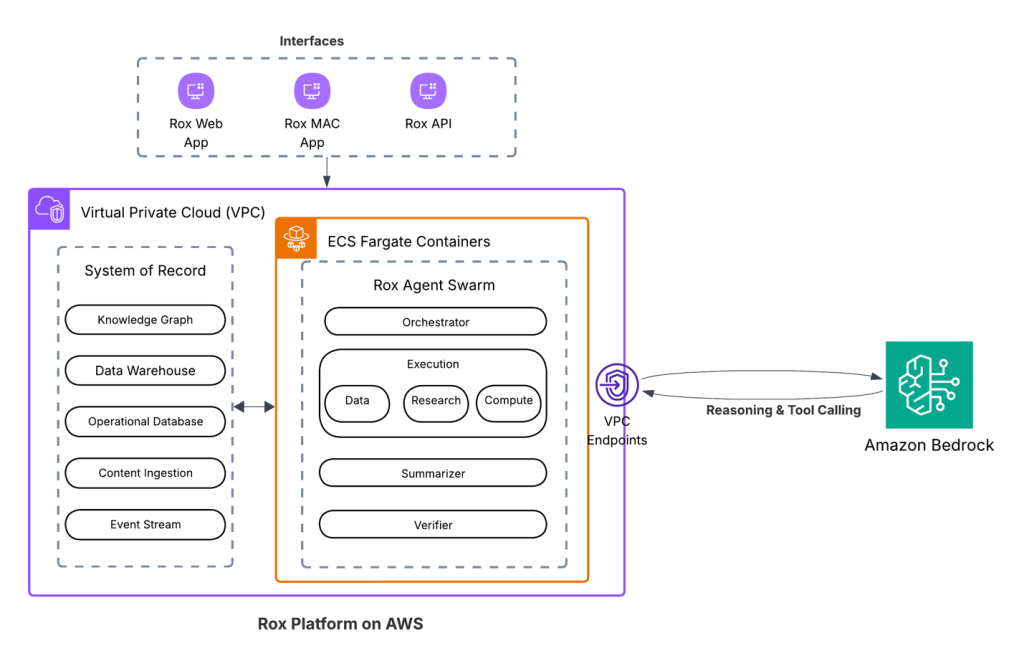
We’re excited to announce that Rox is generally available, with Rox infrastructure built on AWS and delivered across web, Slack, macOS, and iOS. In this post, we share how Rox accelerates sales productivity with AI agents powered by Amazon...
1 day ago
0
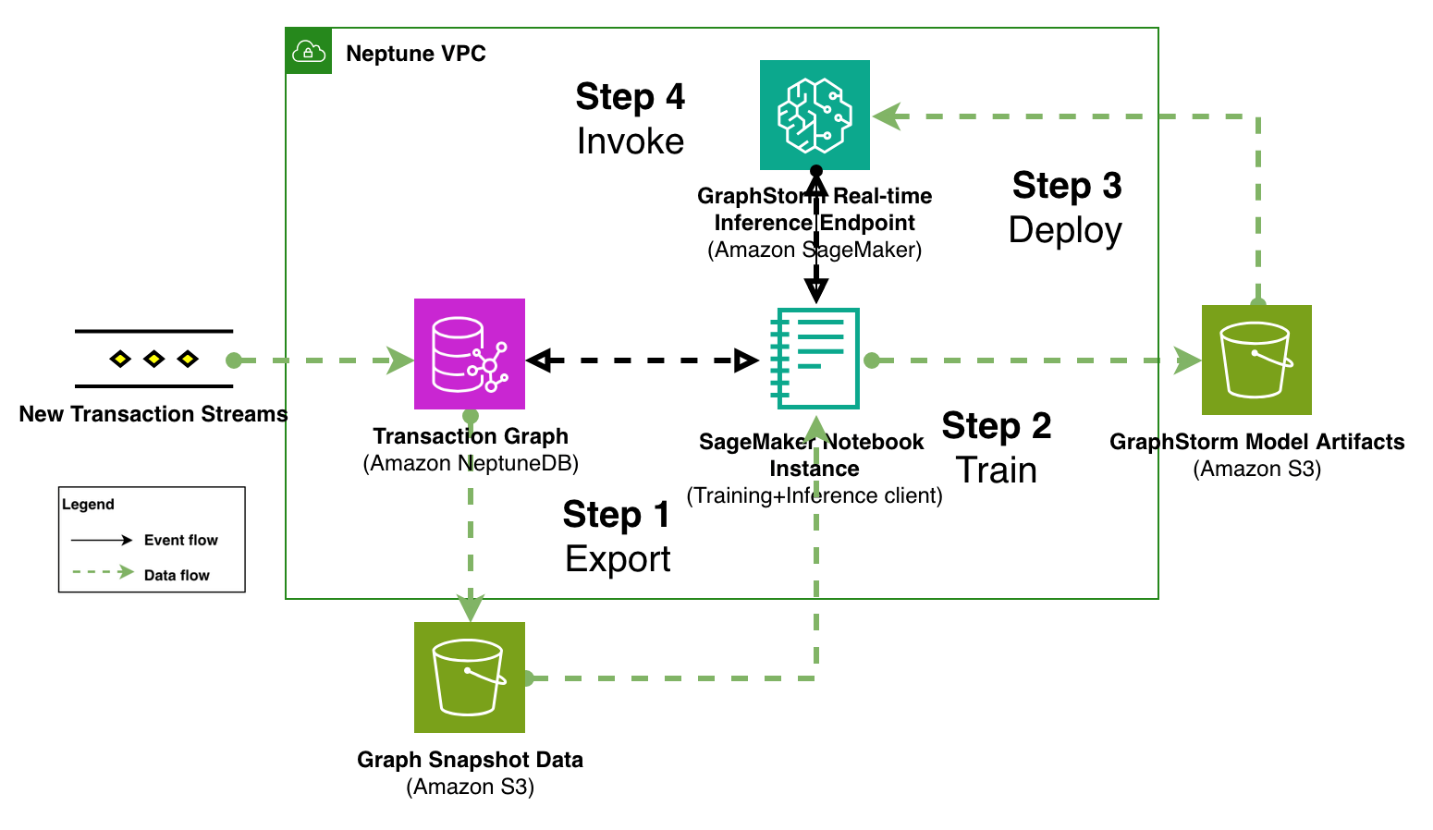
Modernize fraud prevention: GraphStorm v0.5 for re...
In this post, we demonstrate how to implement real-time fraud prevention using GraphStorm v0.5's new capabilities for deploying graph neural network (GNN) models through Amazon SageMaker. We show how to transition from model training to production-ready inference endpoints with...
2 days ago
6

Building health care agents using Amazon Bedrock A...
In this solution, we demonstrate how the user (a parent) can interact with a Strands or LangGraph agent in conversational style and get information about the immunization history and schedule of their child, inquire about the available slots, and...
6 days ago
35
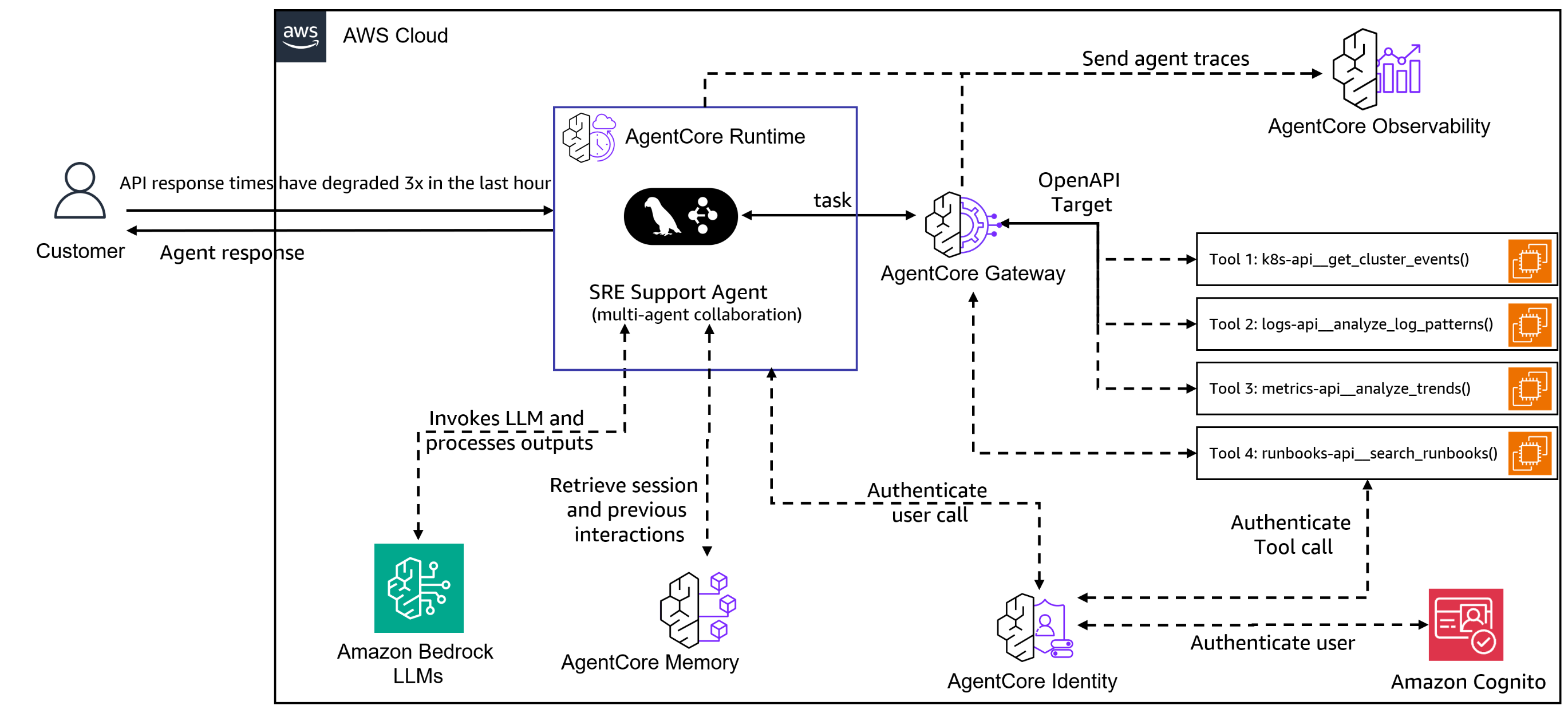
Build multi-agent site reliability engineering ass...
In this post, we demonstrate how to build a multi-agent SRE assistant using Amazon Bedrock AgentCore, LangGraph, and the Model Context Protocol (MCP). This system deploys specialized AI agents that collaborate to provide the deep, contextual intelligence that modern...
6 days ago
32
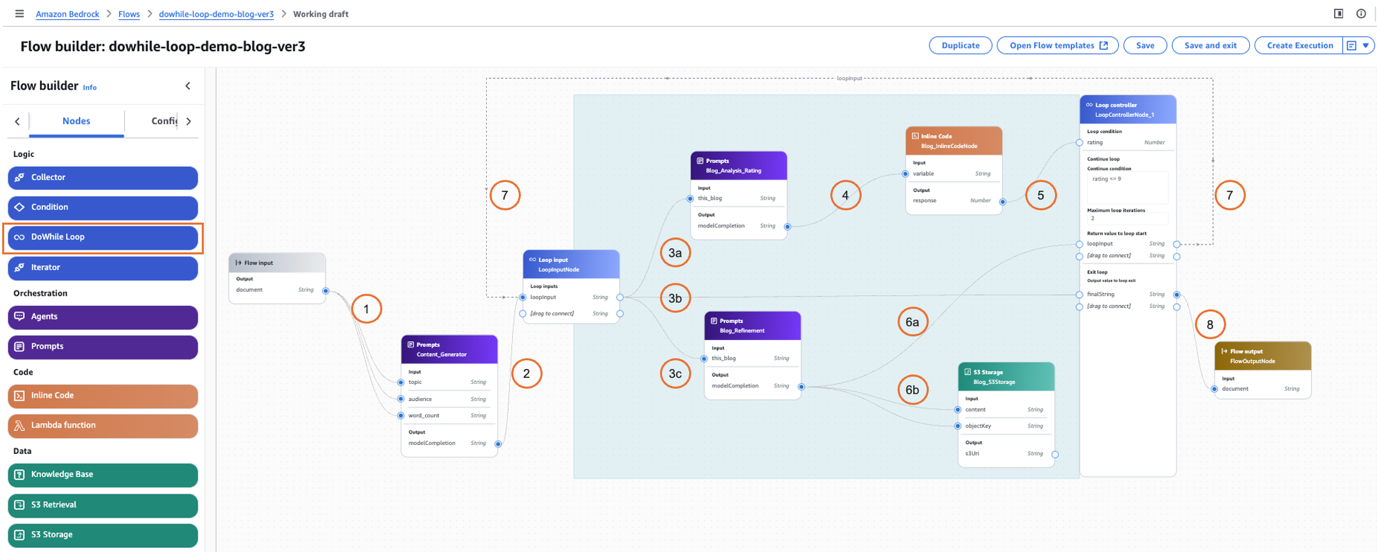
DoWhile loops now supported in Amazon Bedrock Flow...
Today, we are excited to announce support for DoWhile loops in Amazon Bedrock Flows. With this powerful new capability, you can create iterative, condition-based workflows directly within your Amazon Bedrock flows, using Prompt nodes, AWS Lambda functions, Amazon Bedrock...
1 week ago
39
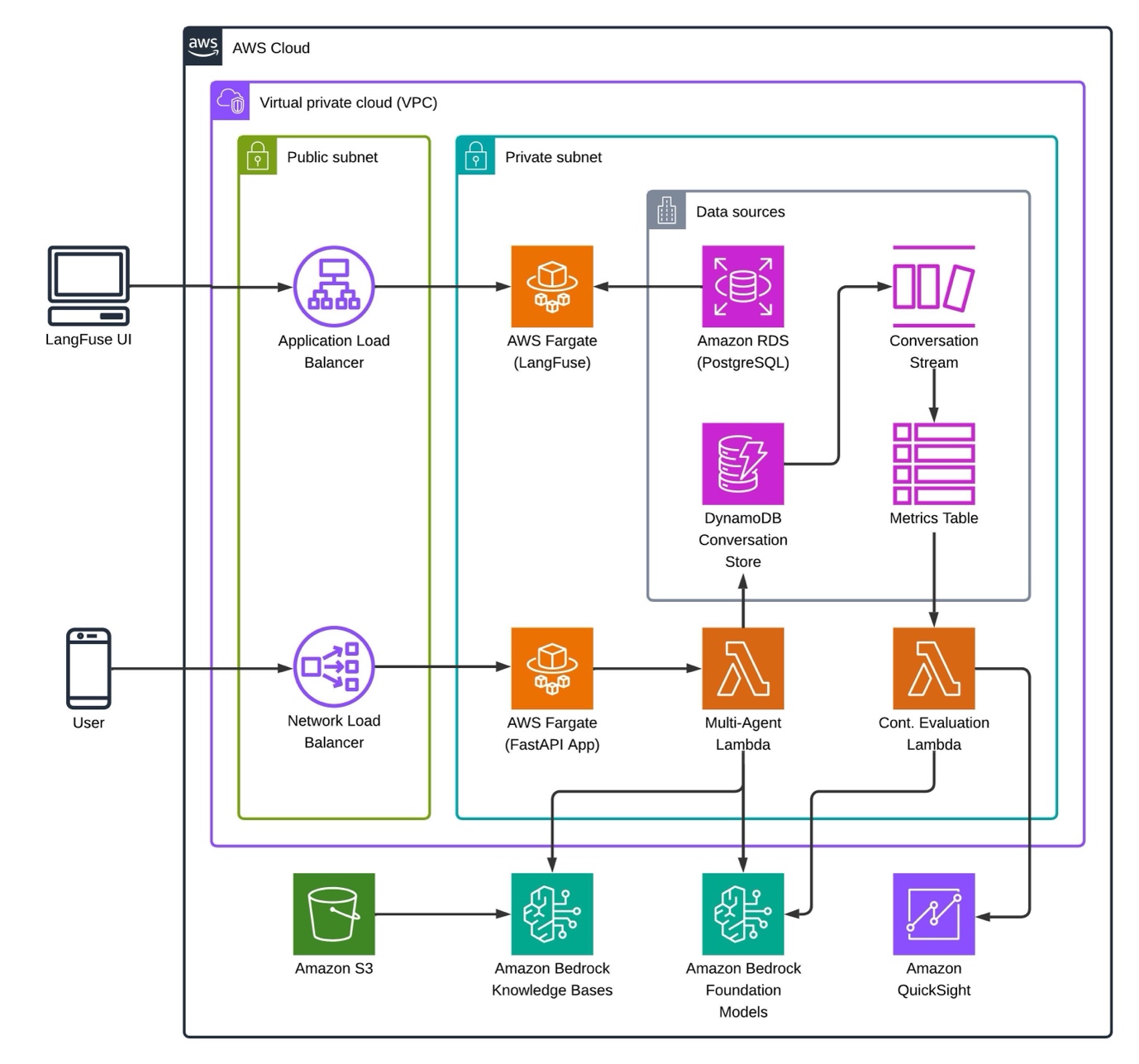
How PropHero built an intelligent property investm...
In this post, we explore how we built a multi-agent conversational AI system using Amazon Bedrock that delivers knowledge-grounded property investment advice. We explore the agent architecture, model selection strategy, and comprehensive continuous evaluation system that facilitates quality conversations...
1 week ago
33
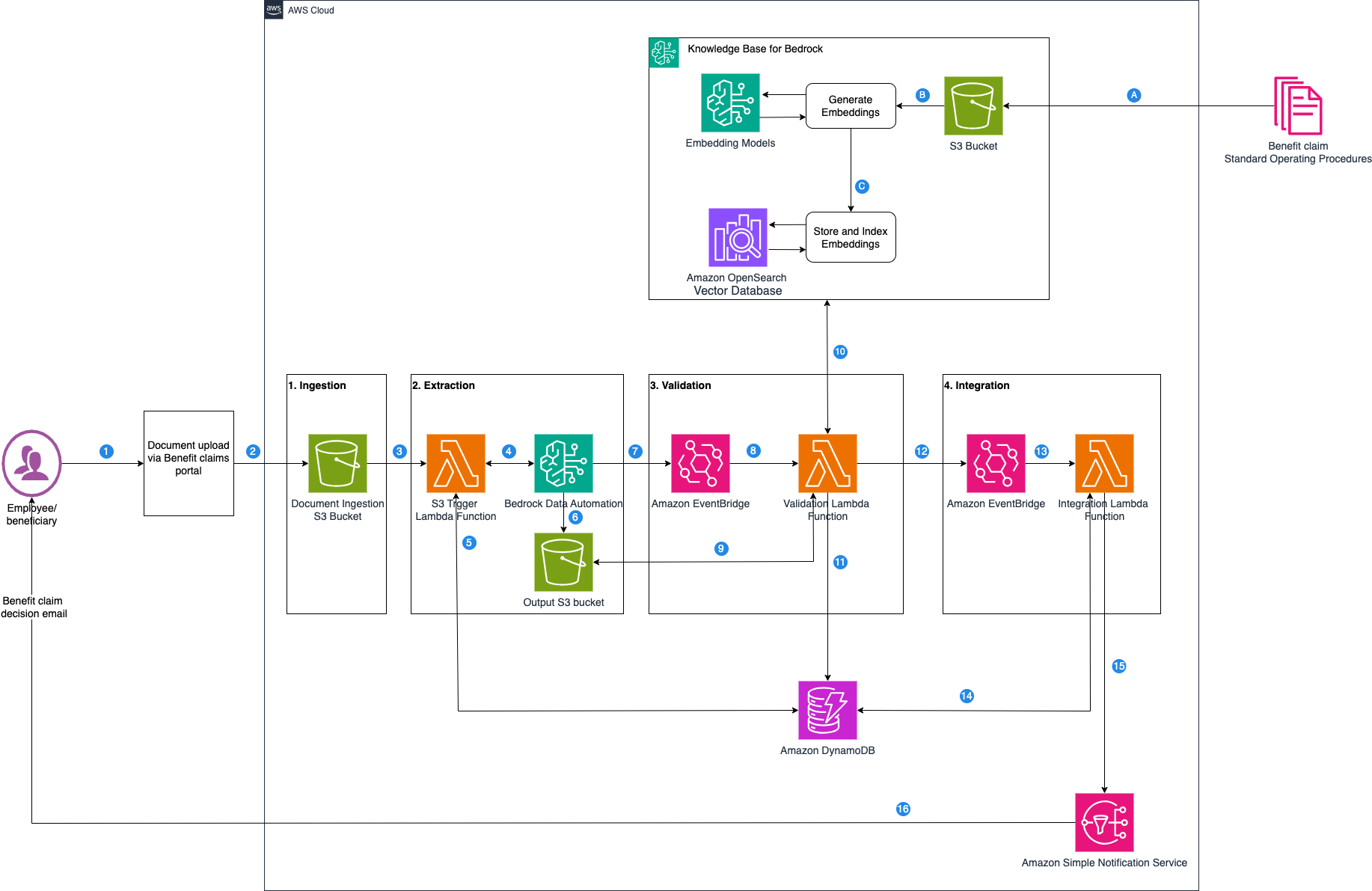
Accelerate benefits claims processing with Amazon ...
In the benefits administration industry, claims processing is a vital operational pillar that makes sure employees and beneficiaries receive timely benefits, such as health, dental, or disability payments, while controlling costs and adhering to regulations like HIPAA and ERISA....
1 week ago
36
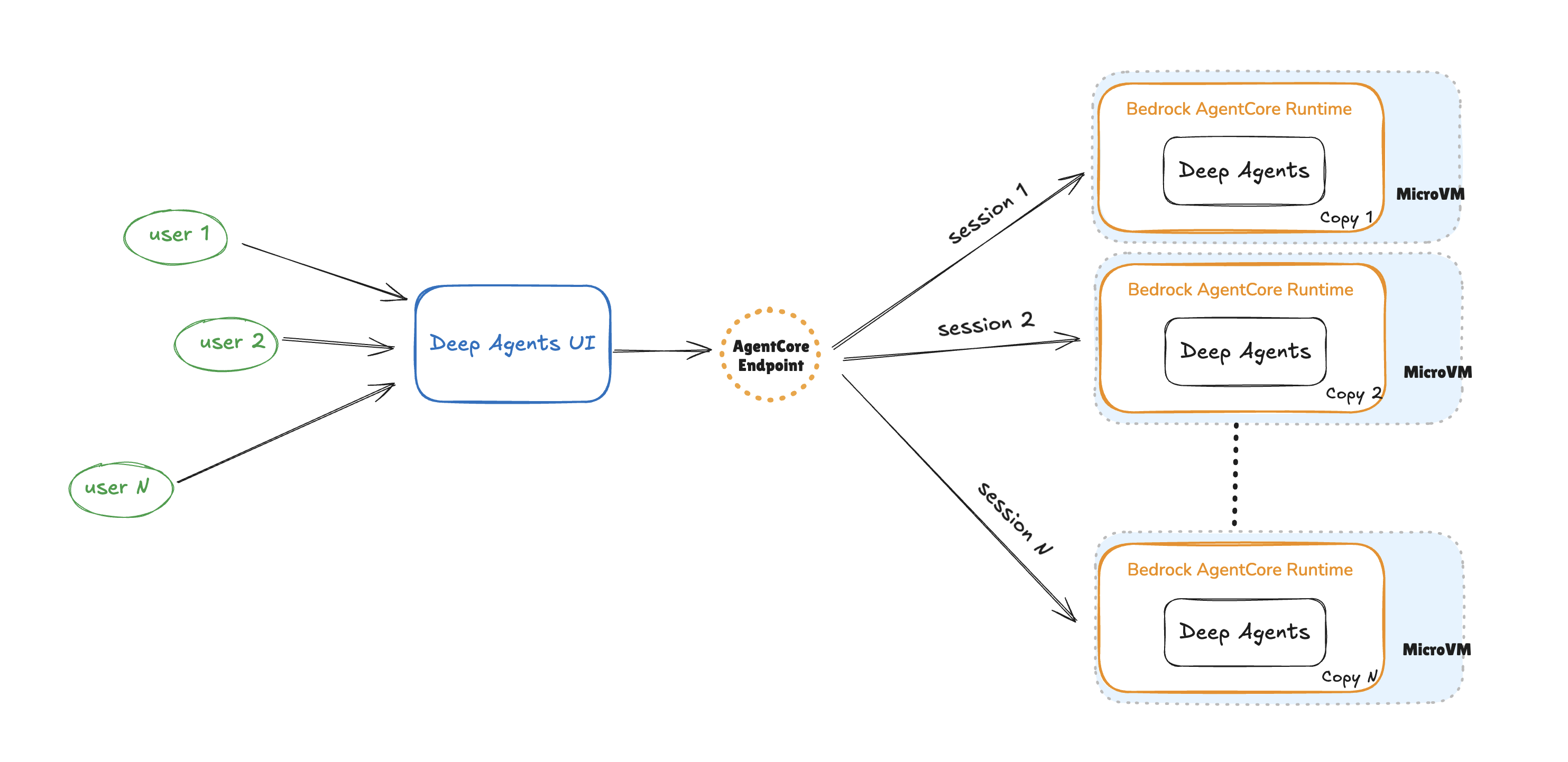
Running deep research AI agents on Amazon Bedrock ...
AI agents are evolving beyond basic single-task helpers into more powerful systems that can plan, critique, and collaborate with other agents to solve complex problems. Deep Agents—a recently introduced framework built on LangGraph—bring these capabilities to life, enabling multi-agent...
1 week ago
40
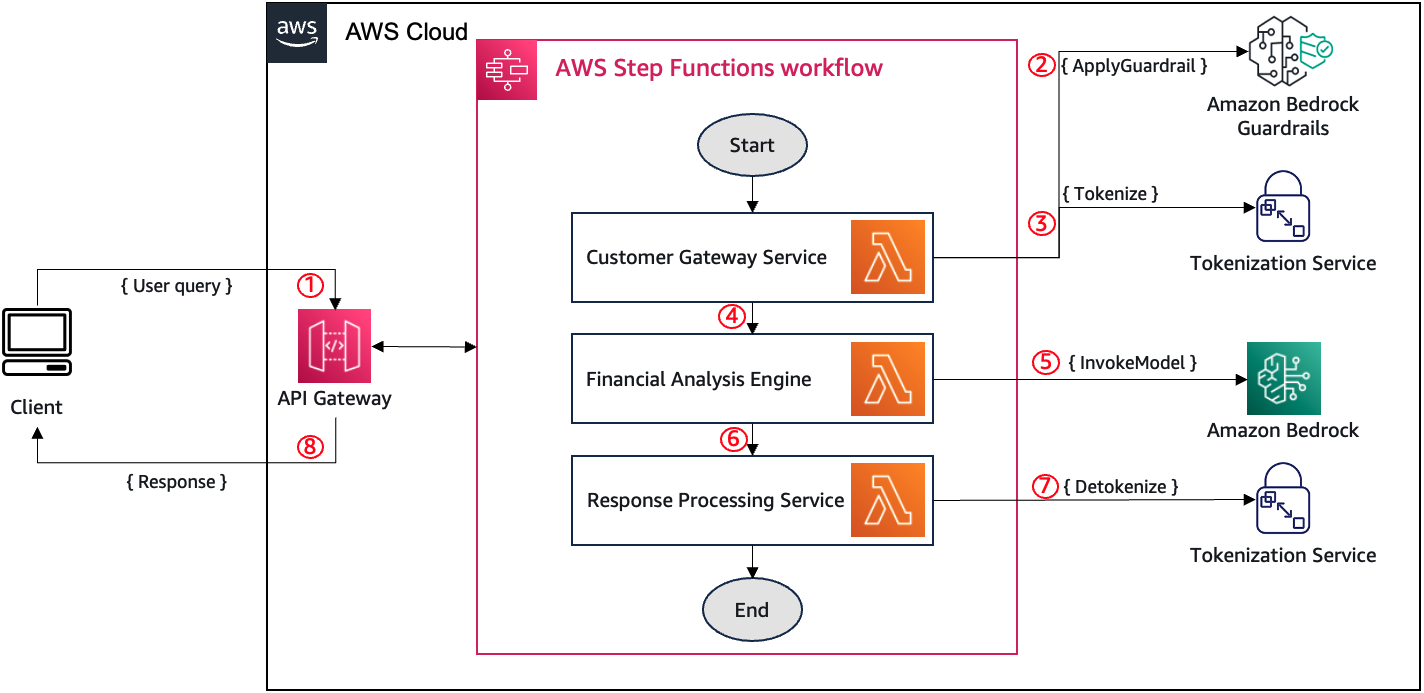
Integrate tokenization with Amazon Bedrock Guardra...
In this post, we show you how to integrate Amazon Bedrock Guardrails with third-party tokenization services to protect sensitive data while maintaining data reversibility. By combining these technologies, organizations can implement stronger privacy controls while preserving the functionality of...
1 week ago
45
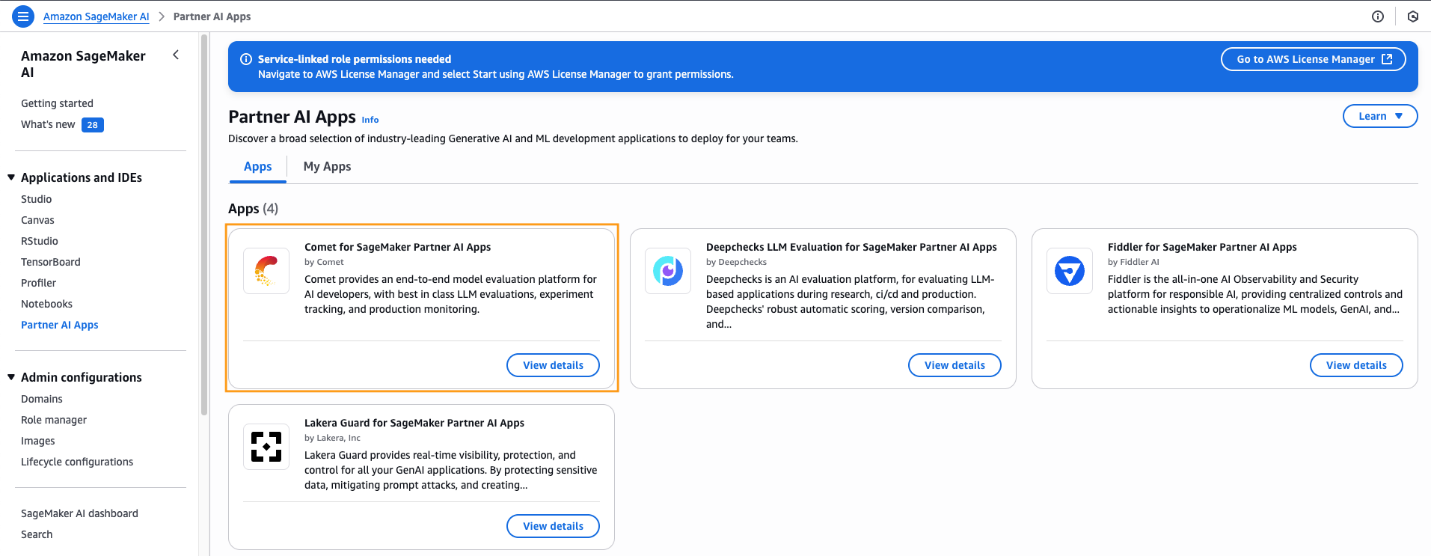
Rapid ML experimentation for enterprises with Amaz...
In this post, we showed how to use SageMaker and Comet together to spin up fully managed ML environments with reproducibility and experiment tracking capabilities.
1 week ago
28
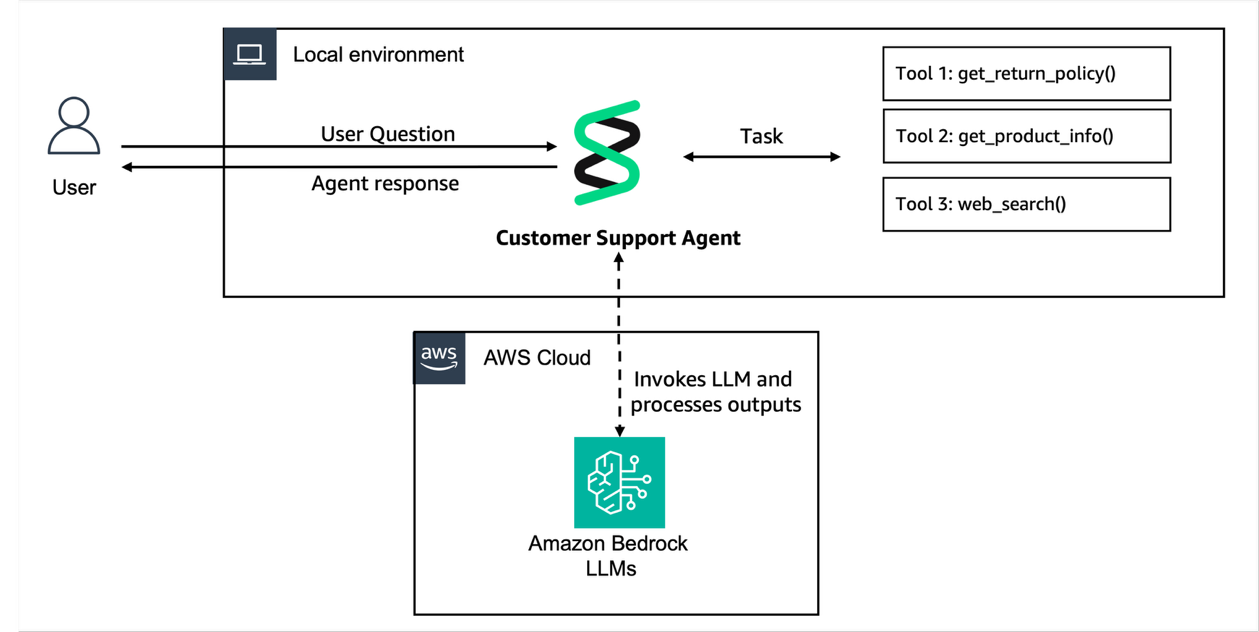
Move your AI agents from proof of concept to produ...
This post explores how Amazon Bedrock AgentCore helps you transition your agentic applications from experimental proof of concept to production-ready systems. We follow the journey of a customer support agent that evolves from a simple local prototype to a...
1 week ago
23

Scale visual production using Stability AI Image S...
This post was written with Alex Gnibus of Stability AI. Stability AI Image Services are now available in Amazon Bedrock, offering ready-to-use media editing capabilities delivered through the Amazon Bedrock API. These image editing tools expand on the capabilities...
2 weeks ago
25

Prompting for precision with Stability AI Image Se...
Amazon Bedrock now offers Stability AI Image Services: 9 tools that improve how businesses create and modify images. The technology extends Stable Diffusion and Stable Image models to give you precise control over image creation and editing. Clear prompts...
2 weeks ago
24
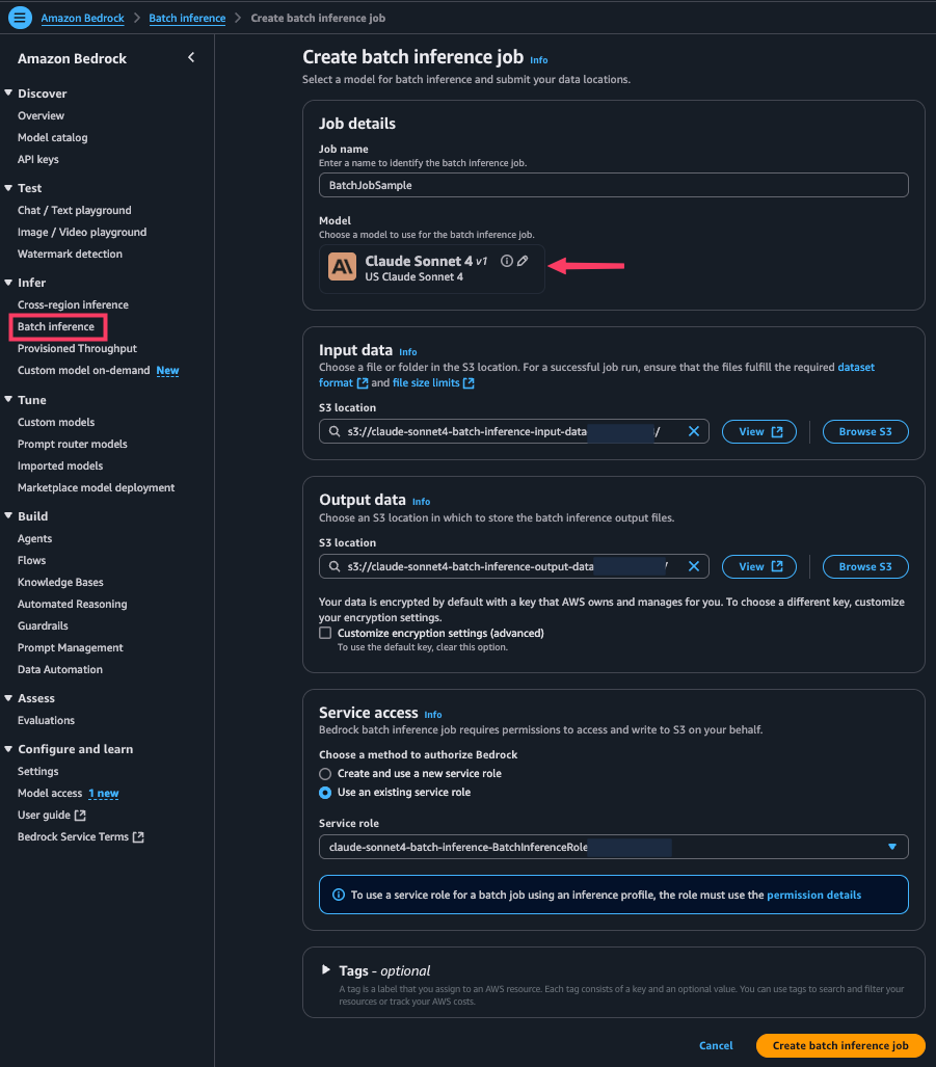
Monitor Amazon Bedrock batch inference using Amazo...
In this post, we explore how to monitor and manage Amazon Bedrock batch inference jobs using Amazon CloudWatch metrics, alarms, and dashboards to optimize performance, cost, and operational efficiency.
2 weeks ago
14
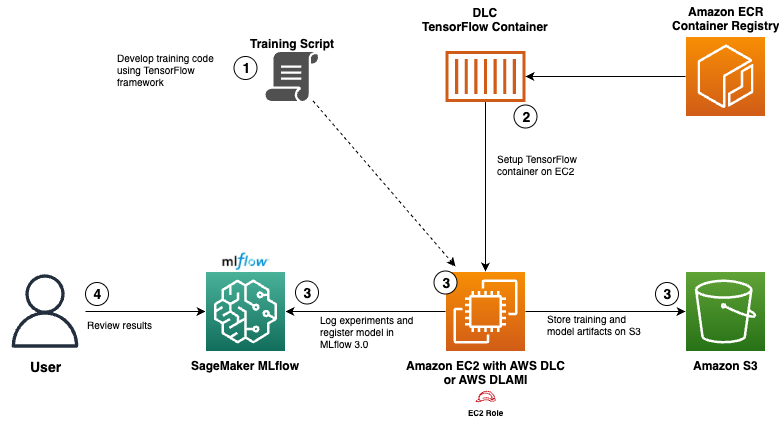
Use AWS Deep Learning Containers with Amazon SageM...
In this post, we show how to integrate AWS DLCs with MLflow to create a solution that balances infrastructure control with robust ML governance. We walk through a functional setup that your team can use to meet your specialized...
2 weeks ago
18
Popular


The 13 visual principles of design (with examples)


GEO vs. SEO: A Comparative Guide for Digital Marketers





 English (US) ·
English (US) ·