
AWS Machine Learning Blog
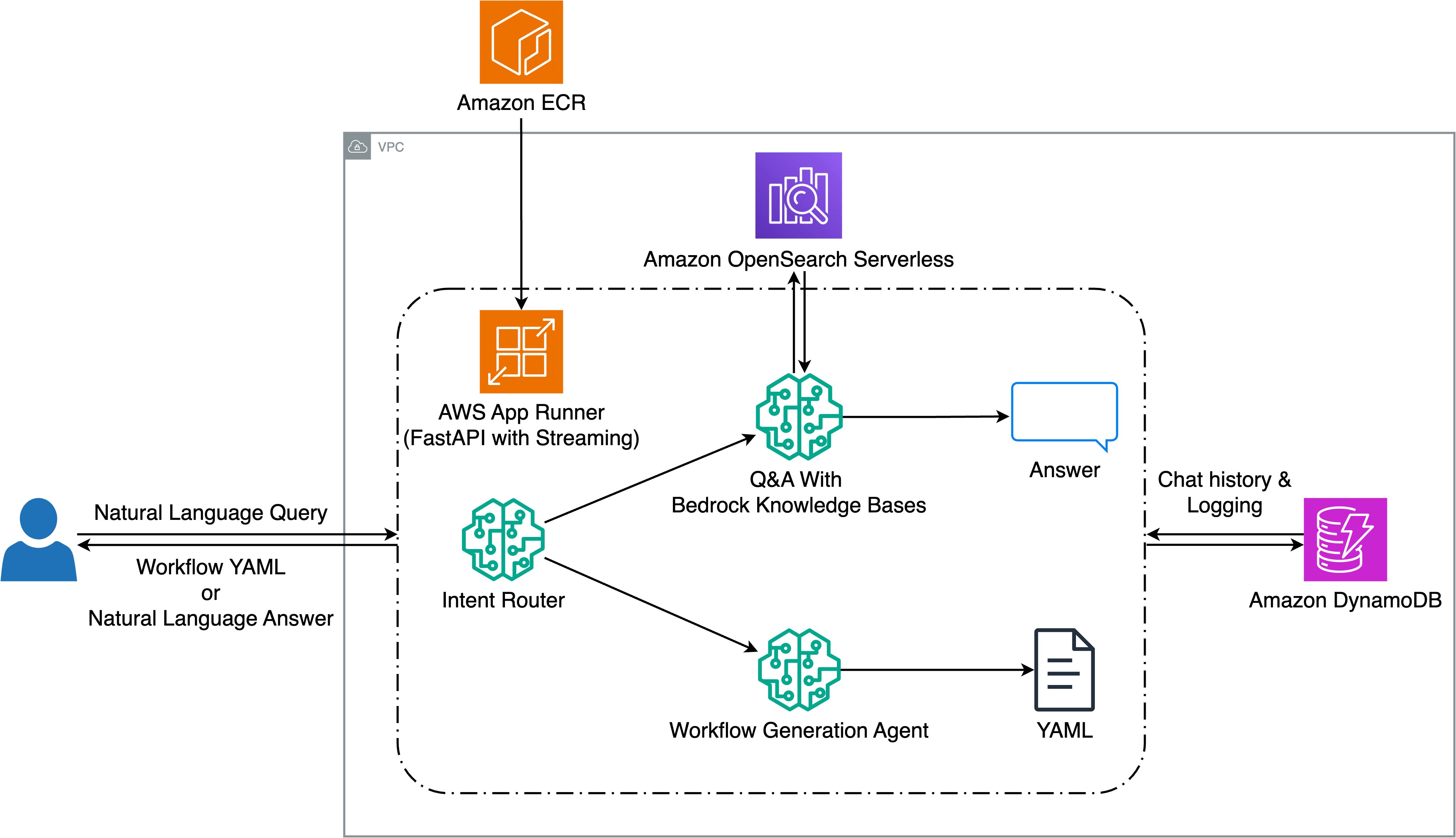
Halliburton enhances seismic workflow creation wit...
Seismic data analysis is an essential component of energy exploration, but configuring complex processing workflows has traditionally been a time-consuming and error-prone challenge. Halliburton’s Seismic Engine, a cloud-native application for seismic data processing, is a powerful tool that previously...
 15 hours ago
3
15 hours ago
3
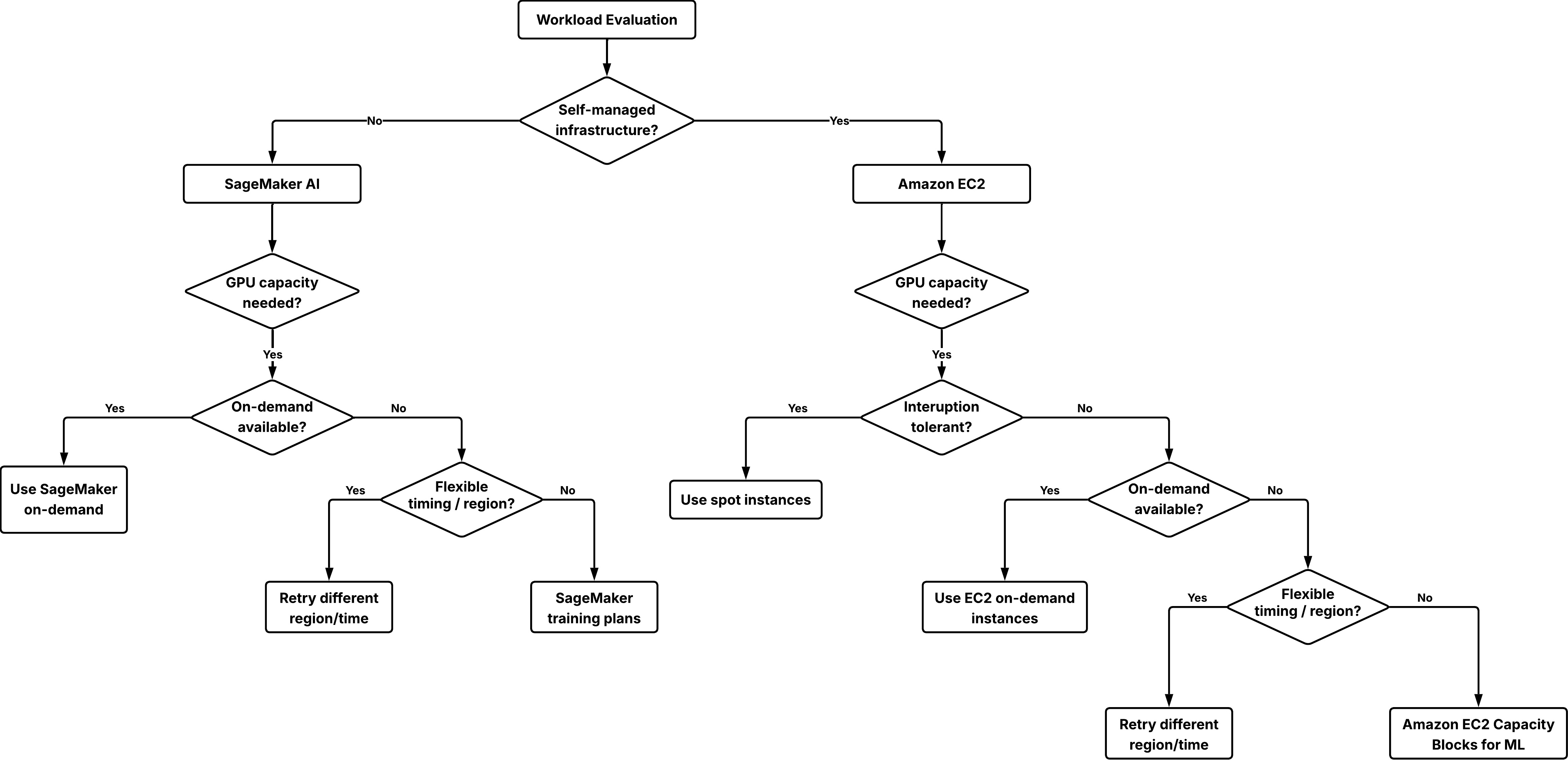
Secure short-term GPU capacity for ML workloads wi...
In this post, you will learn how to secure reserved GPU capacity for short-term workloads using Amazon Elastic Compute Cloud (Amazon EC2) Capacity Blocks for ML and Amazon SageMaker training plans. These solutions can address GPU availability challenges when...
1 day ago
1
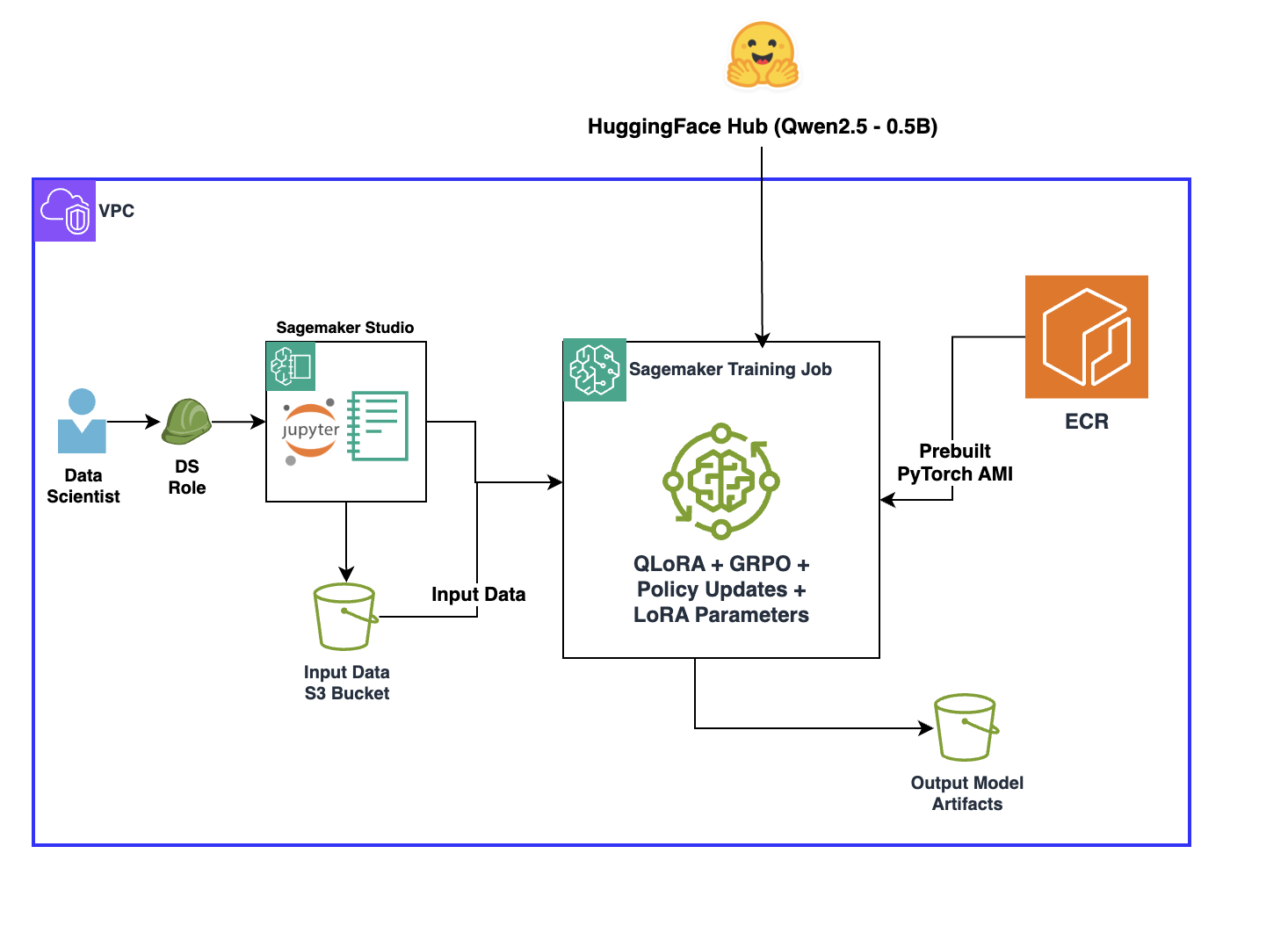
Overcoming reward signal challenges: Verifiable re...
In this post, you will learn how to implement reinforcement learning with verifiable rewards (RLVR) to introduce verification and transparency into reward signals to improve training performance. This approach works best when outputs can be objectively verified for correctness,...
1 day ago
1
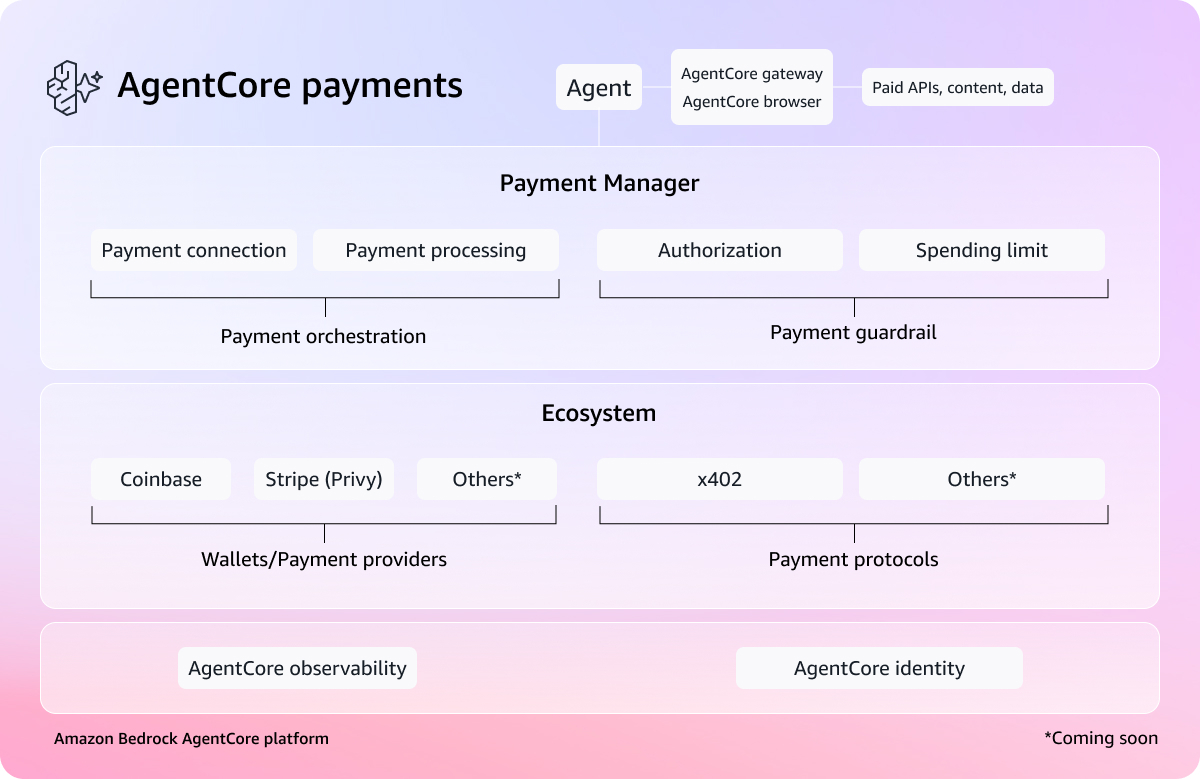
Agents that transact: Introducing Amazon Bedrock A...
Today, we're announcing a preview of Amazon Bedrock AgentCore Payments, a new set of features in Amazon Bedrock AgentCore that enables AI agents to instantly access and pay for what they use. AgentCore Payments was developed in partnership with...
1 day ago
4
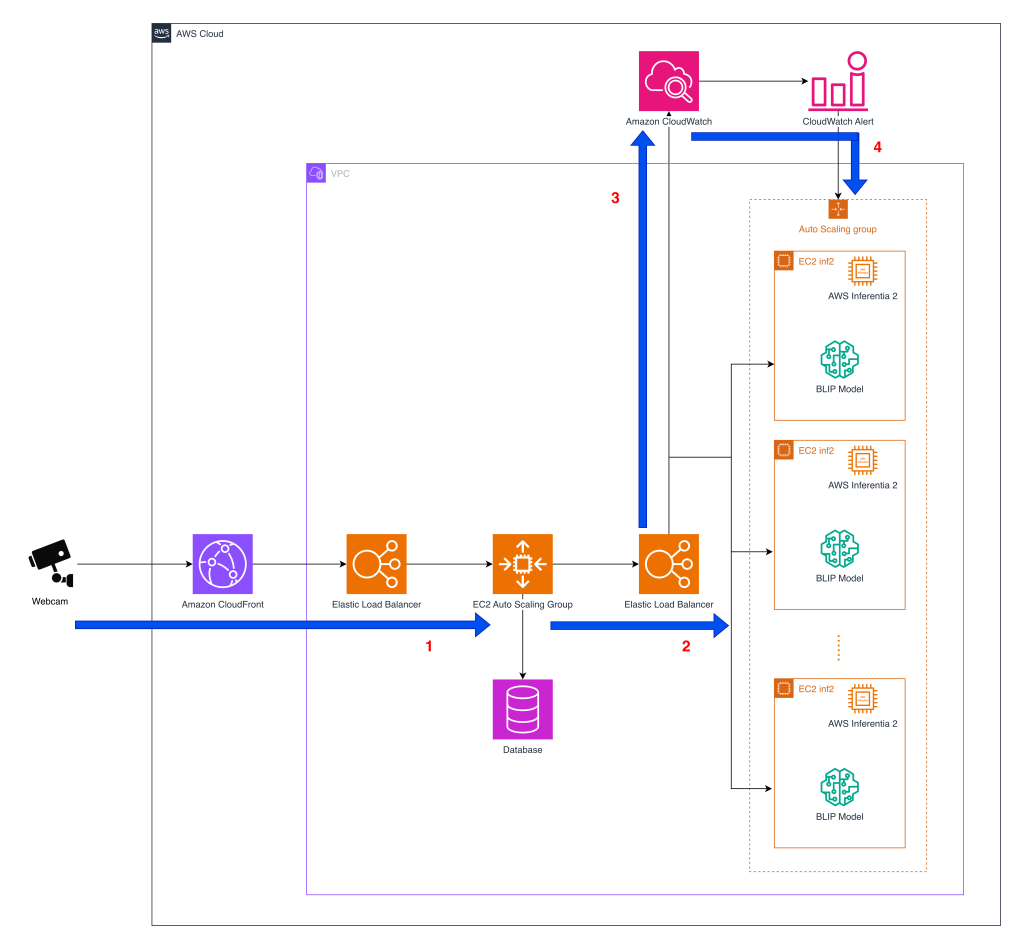
Cost effective deployment of vision-language model...
Tomofun, the Taiwan-headquartered pet-tech startup behind the Furbo Pet Camera, is redefining how pet owners interact with their pets remotely. To reduce costs and maintain accuracy, Tomofun turned to EC2 Inf2 instances powered by AWS Inferentia2, the Amazon purpose-built AI...
2 days ago
0
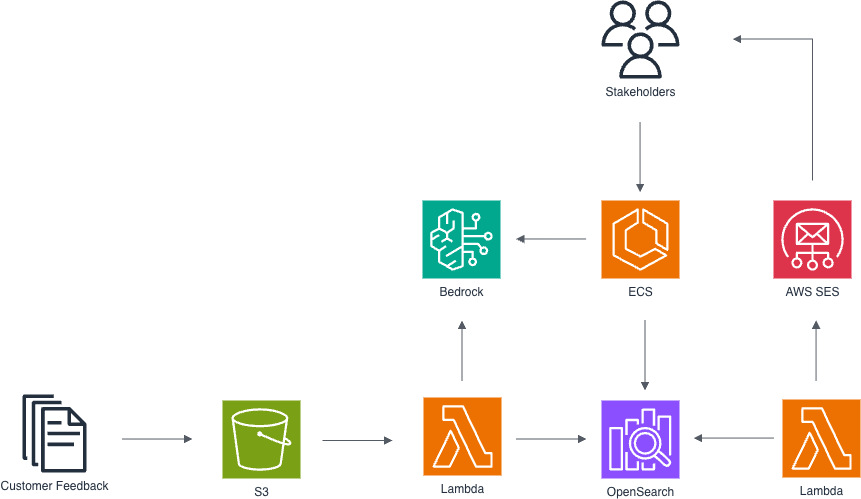
How Hapag-Lloyd uses Amazon Bedrock to transform c...
Hapag-Lloyd's Digital Customer Experience and Engineering team, distributed between Hamburg and Gdańsk, drives digital innovation by developing and maintaining customer-facing web and mobile products. In this post, we walk you through our generative AI–powered feedback analysis solution built using...
3 days ago
2

Streamlining generative AI development with MLflow...
Today, we’re excited to announce that Amazon SageMaker AI MLflow Apps now support MLflow version 3.10, bringing enhanced capabilities for generative AI development and streamlined experiment tracking to your generative AI workflows. Building on the foundations established with Amazon...
3 days ago
2

Introducing OS Level Actions in Amazon Bedrock Age...
We’re announcing OS Level Actions for AgentCore Browser. This new capability unblocks these scenarios by exposing direct OS control through the InvokeBrowser API, so agents can interact with content visible on the screen, not only what's accessible through the...
3 days ago
2
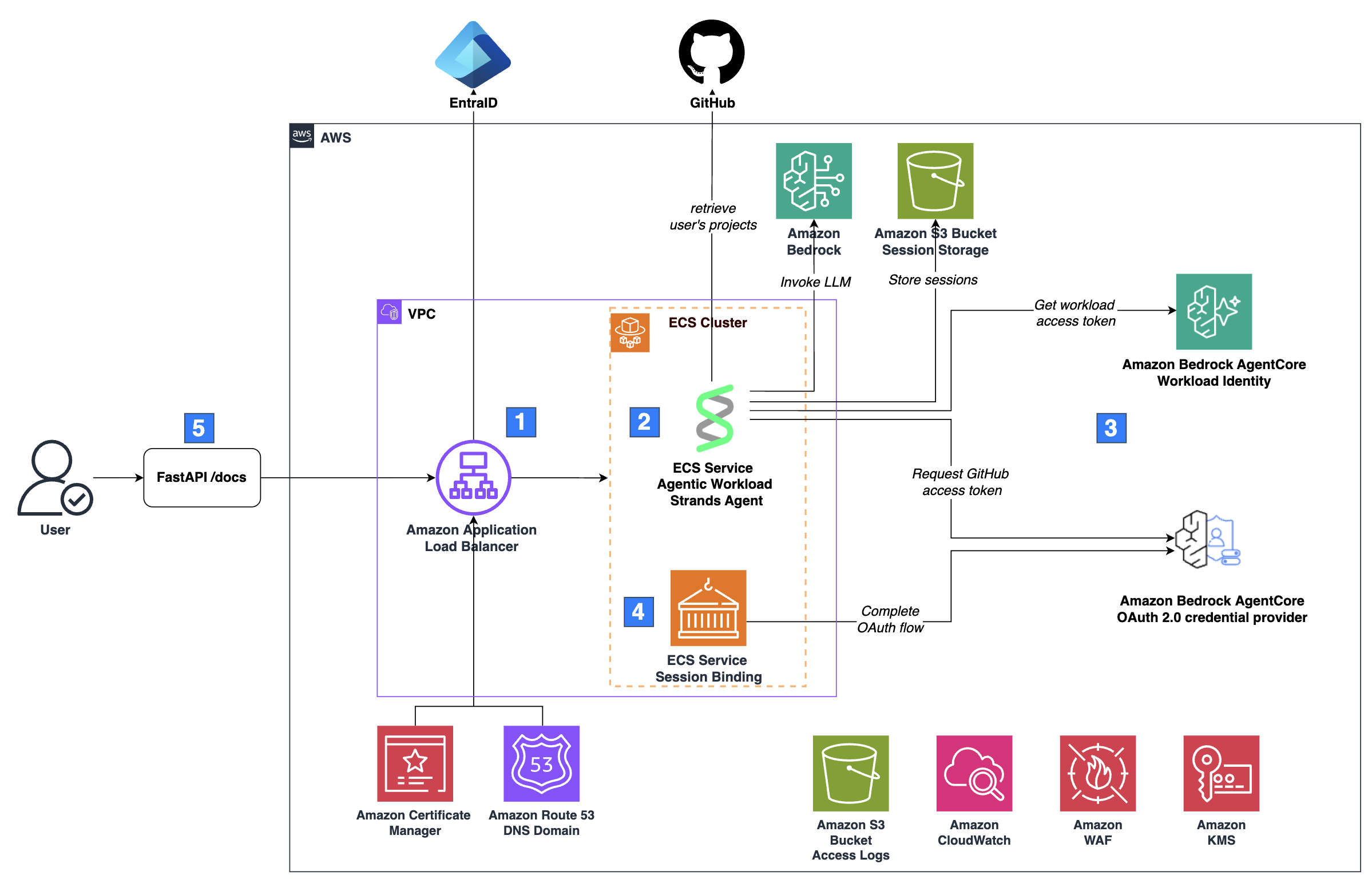
Secure AI agents with Amazon Bedrock AgentCore Ide...
AI agents in production require secure access to external services. Amazon Bedrock AgentCore Identity, available as a standalone service, secures how your AI agents access external services whether they run on compute platforms like Amazon ECS, Amazon EKS, AWS...
3 days ago
0
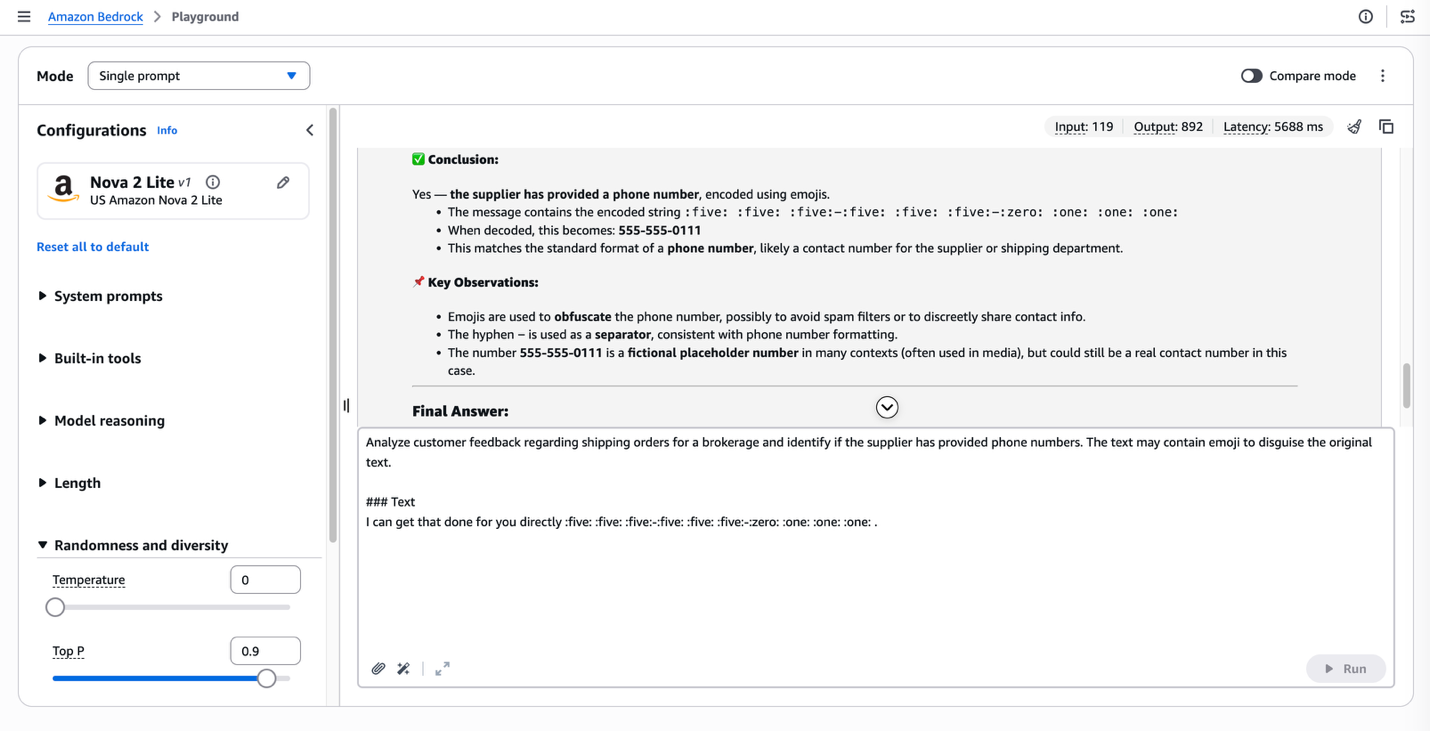
Intelligence-driven message defense and insights u...
In this post, you will learn how you can use Amazon Nova Foundation Models in Amazon Bedrock to apply generative AI techniques for both business protection and enhancement. You can identify obvious and disguised attempts at direct contact while...
3 days ago
0
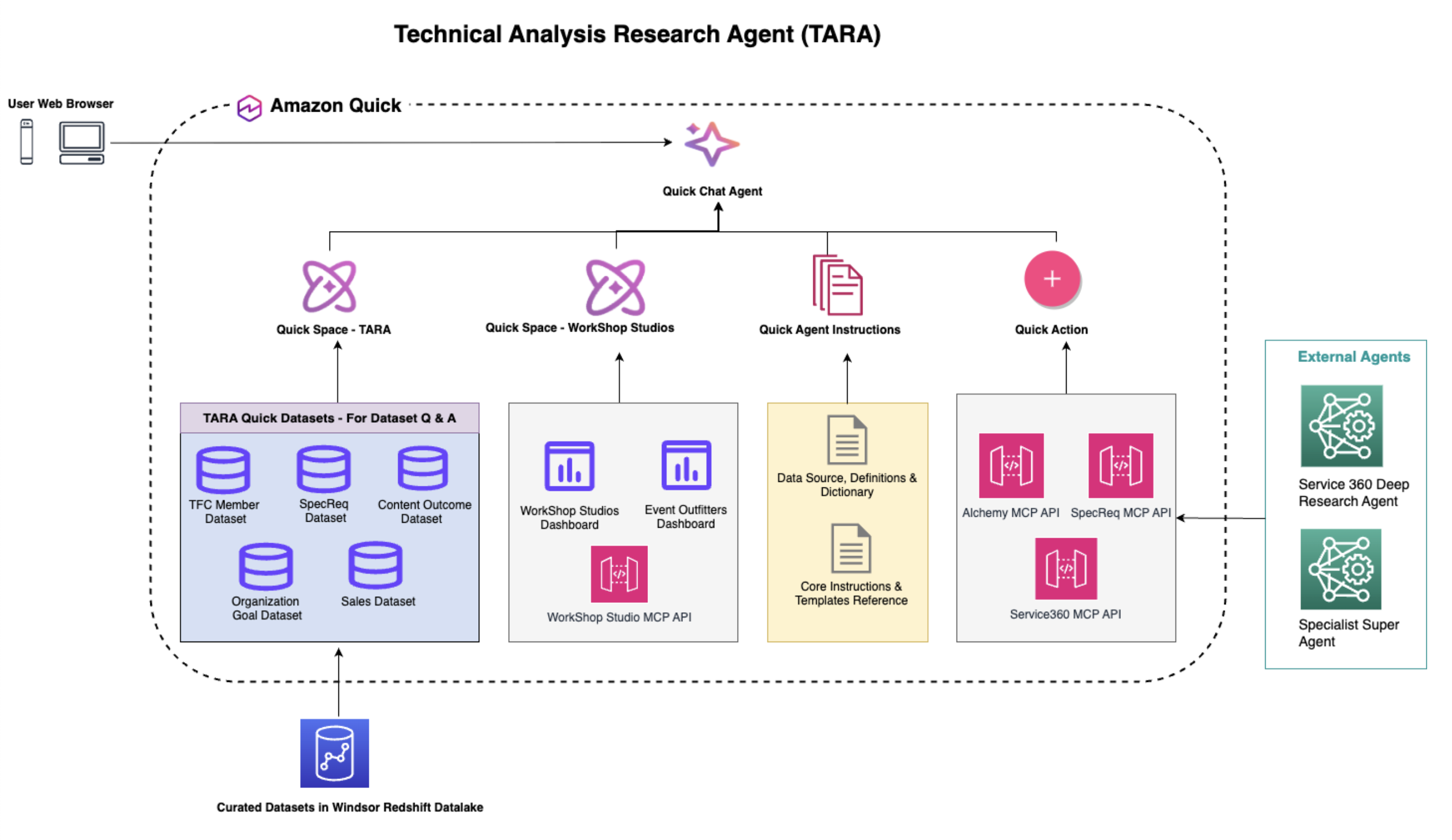
Beyond BI: How the Dataset Q&A feature of Amazon Q...
Business leaders across industries rely on operational dashboards as the shared source of truth that their teams execute against daily. But dashboards are built to answer known questions. When teams need to explore further, ad-hoc, multi-dimensional, or unforeseen questions,...
4 days ago
1

Introducing the agent quality loop: AgentCore Opti...
Generate recommendations from production traces, validate them with batch evaluation and A/B testing, and ship with confidence. AI agents that perform well at launch don’t stay that way. As models evolve, user behavior shifts, and prompts get reused in...
4 days ago
1
Agent-guided workflows to accelerate model customi...
Amazon SageMaker AI now offers an agentic experience that changes this. Developers describe their use case using natural language, and the AI coding agent streamlines the entire journey, from use case definition and data preparation through technique selection, evaluation,...
4 days ago
2
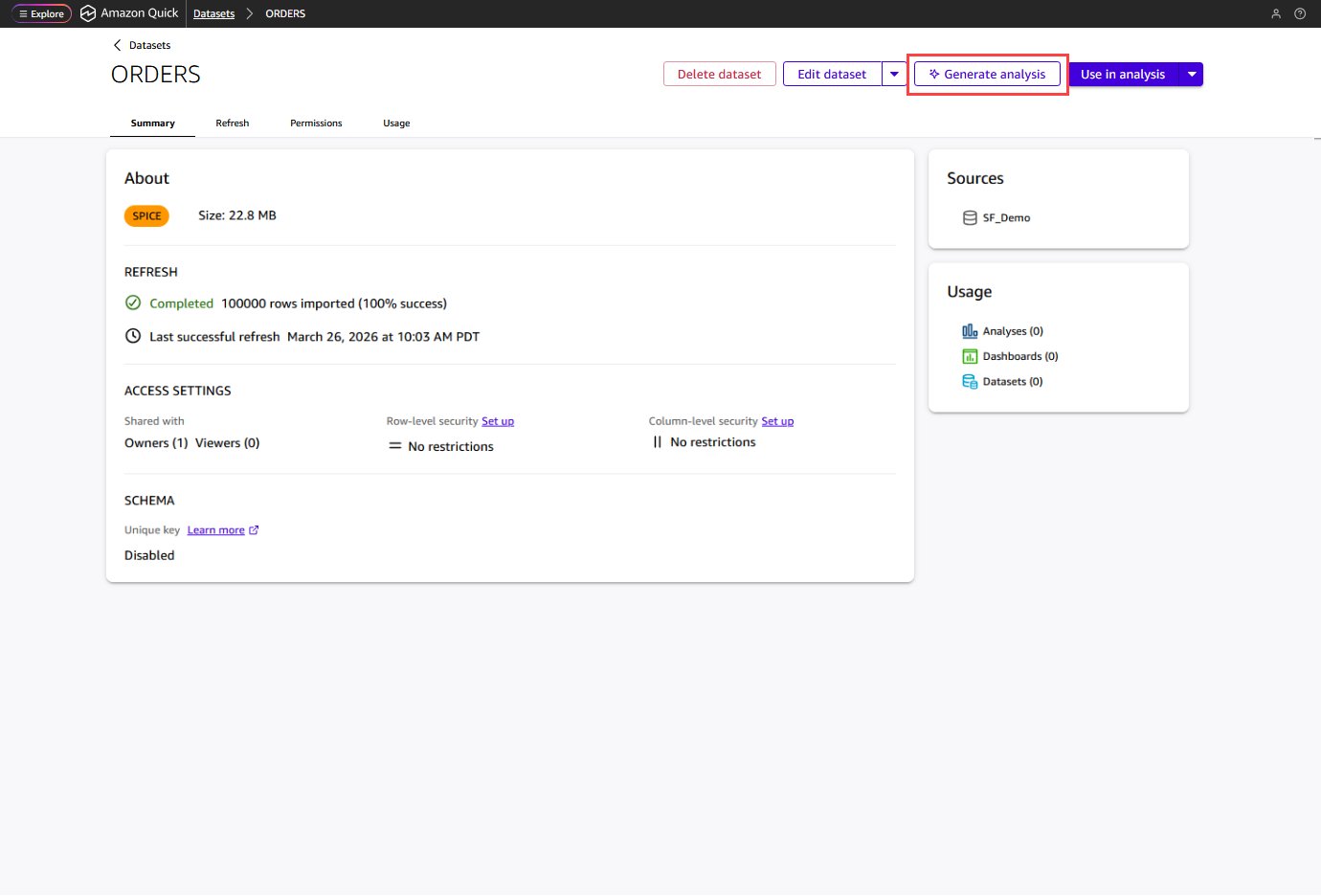
Generate dashboards from natural language prompts ...
Building meaningful dashboards demands hours of manual setup, even for experienced BI professionals. Amazon Quick now generates complete multi-sheet dashboards from natural language prompts, taking you from one or more datasets to a production-ready analysis in minutes. Data analysts building...
4 days ago
1
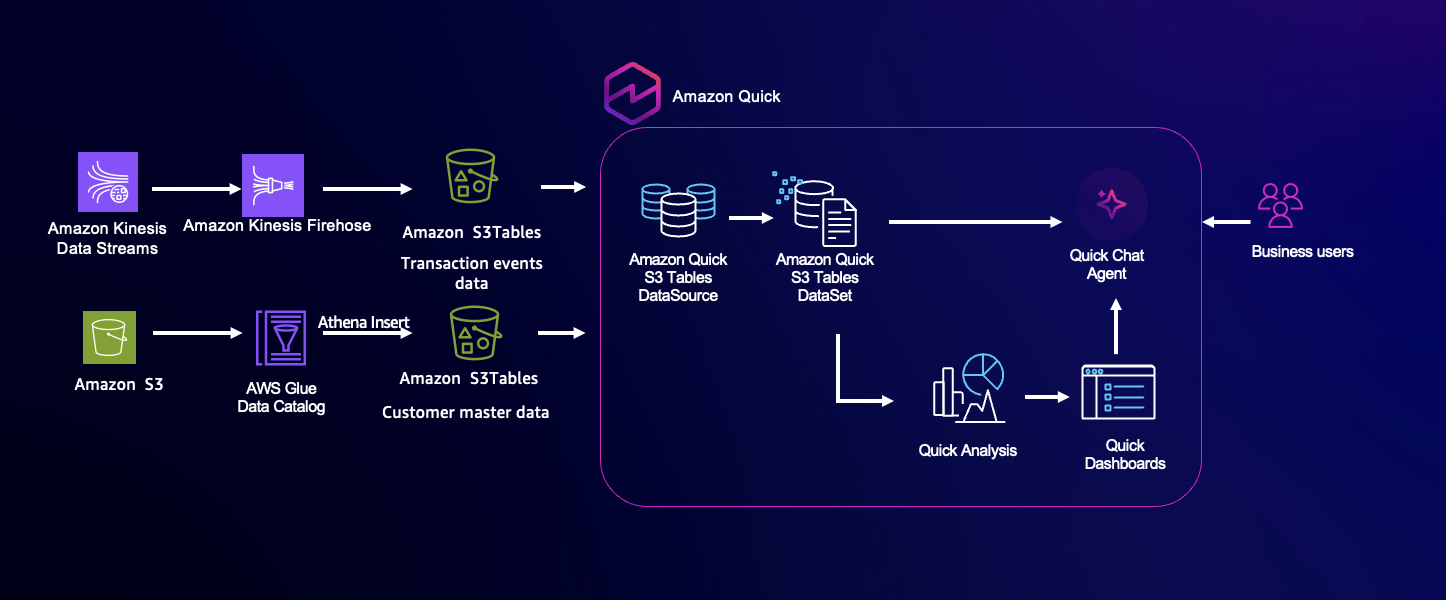
From data lake to AI-ready analytics: Introducing ...
Amazon Quick introduces Amazon S3 Tables (Apache Iceberg tables) as a new data source. With this feature, customers can directly query and visualize Apache Iceberg tables stored in an Amazon S3 table bucket without the need for intermediate data...
4 days ago
3
Introducing Dataset Q&A: Expanding natural languag...
In this post, you learn how to get started with Dataset Q&A, explore real-world use cases with hands-on examples, and discover advanced capabilities like auto-discovery across all your data assets and multi-dataset querying in a single conversation.
4 days ago
3
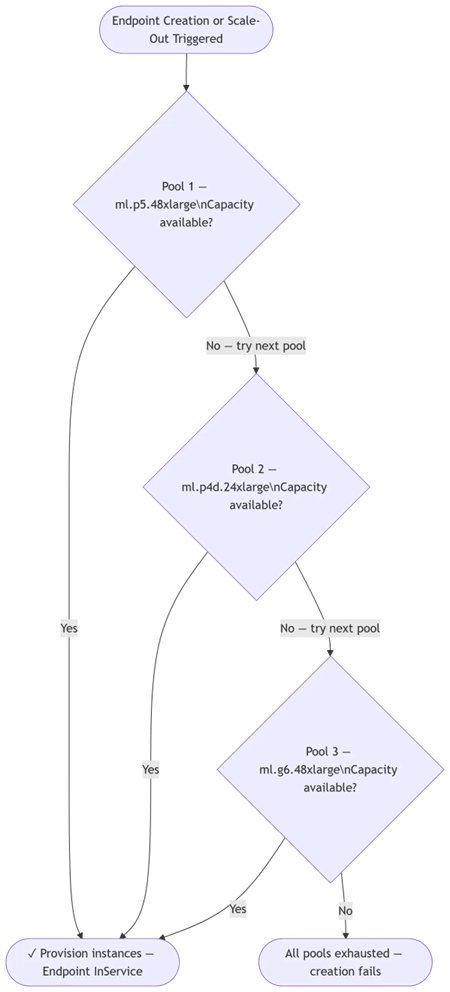
Capacity-aware inference: Automatic instance fallb...
Today, Amazon SageMaker AI introduces capacity aware instance pool for new and existing inference endpoints. You define a prioritized list of instance types, and SageMaker AI automatically works through your list whenever capacity is constrained at creation, during scale-out,...
4 days ago
4
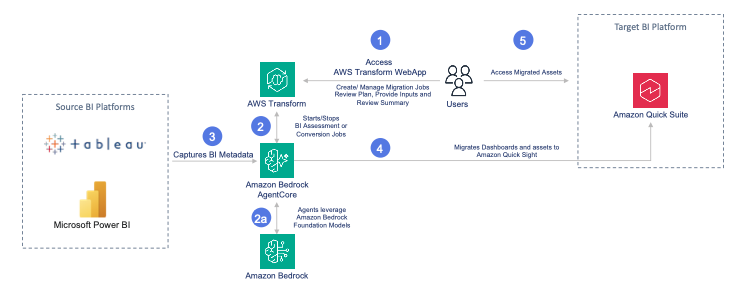
AWS Transform now automates BI migration to Amazon...
In this post, we walk through the full journey, from setting up your migration workspace in AWS Transform to subscribing to partner agents through AWS Marketplace to unlocking Amazon Quick capabilities that change how your organization consumes data.
1 week ago
5









 English (US) ·
English (US) ·