
AWS Machine Learning Blog
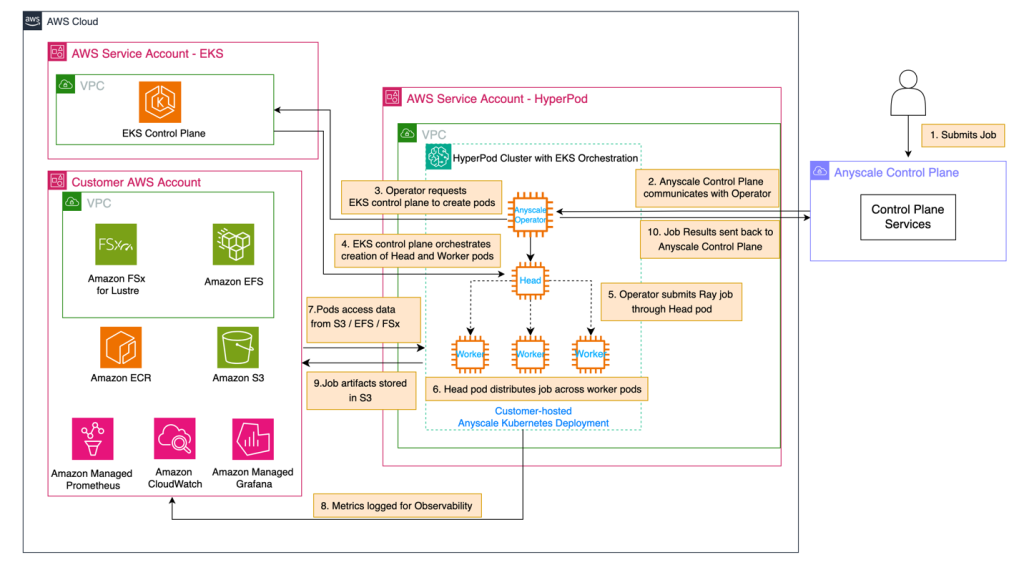
Use Amazon SageMaker HyperPod and Anyscale for nex...
In this post, we demonstrate how to integrate Amazon SageMaker HyperPod with Anyscale platform to address critical infrastructure challenges in building and deploying large-scale AI models. The combined solution provides robust infrastructure for distributed AI workloads with high-performance hardware,...
 1 week ago
10
1 week ago
10
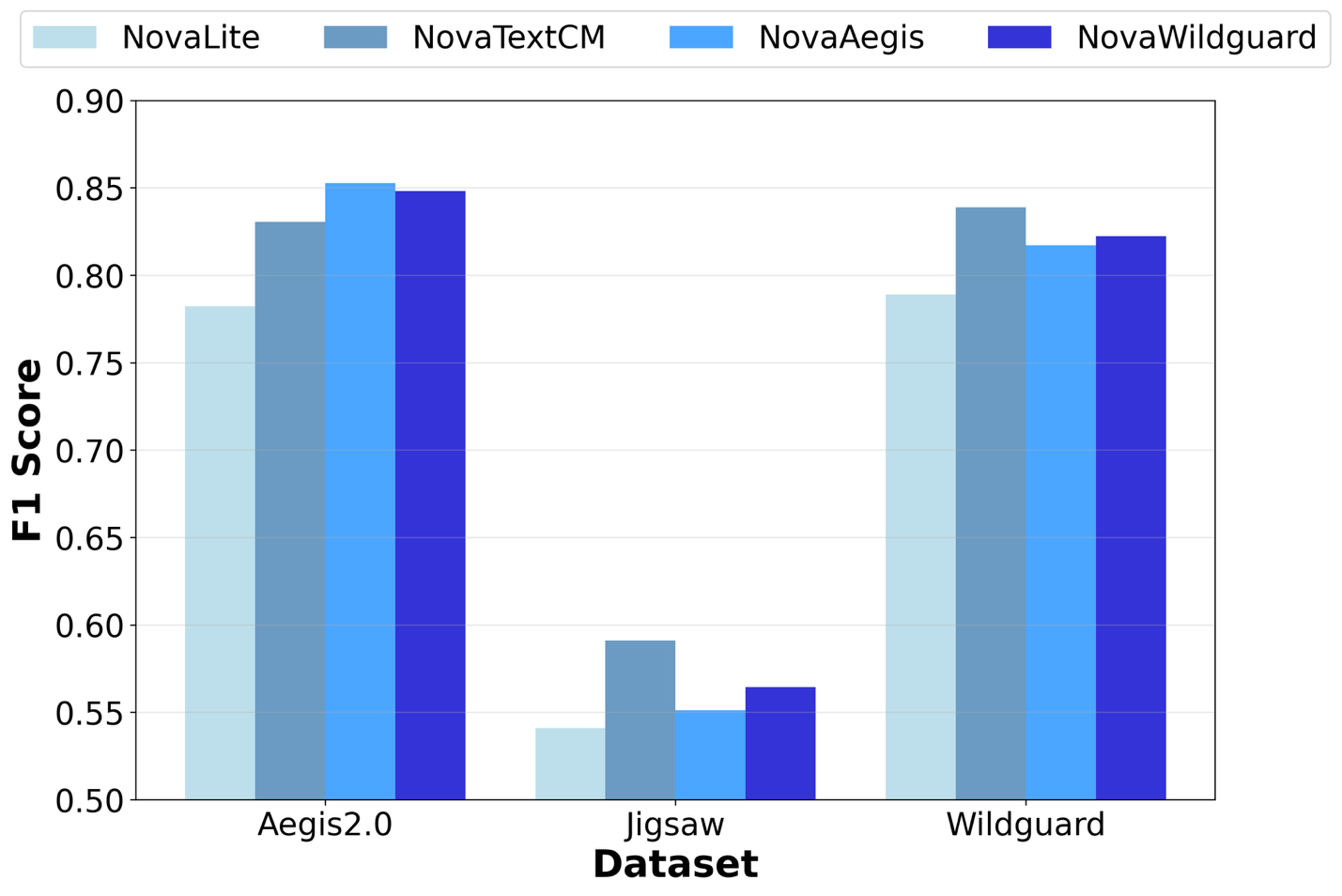
Customizing text content moderation with Amazon No...
In this post, we introduce Amazon Nova customization for text content moderation through Amazon SageMaker AI, enabling organizations to fine-tune models for their specific moderation needs. The evaluation across three benchmarks shows that customized Nova models achieve an average...
1 week ago
11
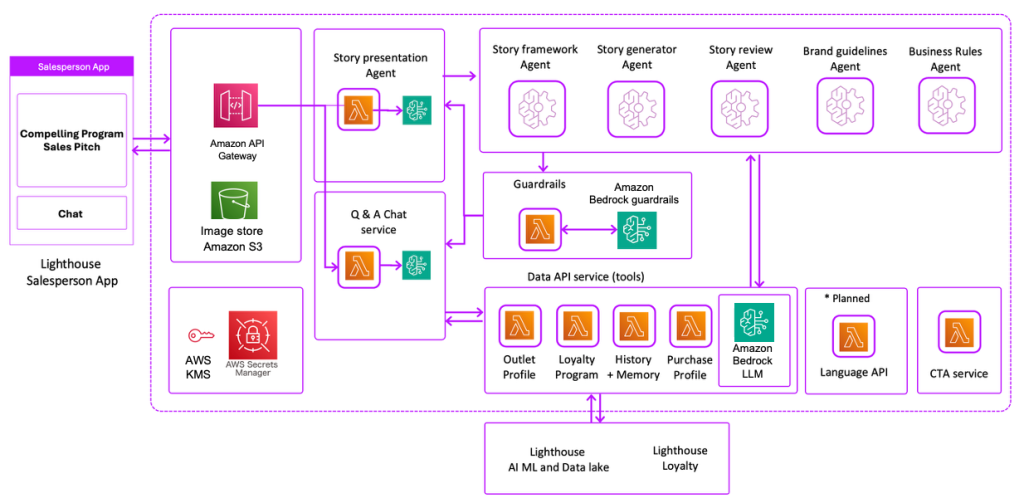
Vxceed builds the perfect sales pitch for sales te...
In this post, we show how Vxceed used Amazon Bedrock to develop this AI-powered multi-agent solution that generates personalized sales pitches for field sales teams at scale.
1 week ago
6
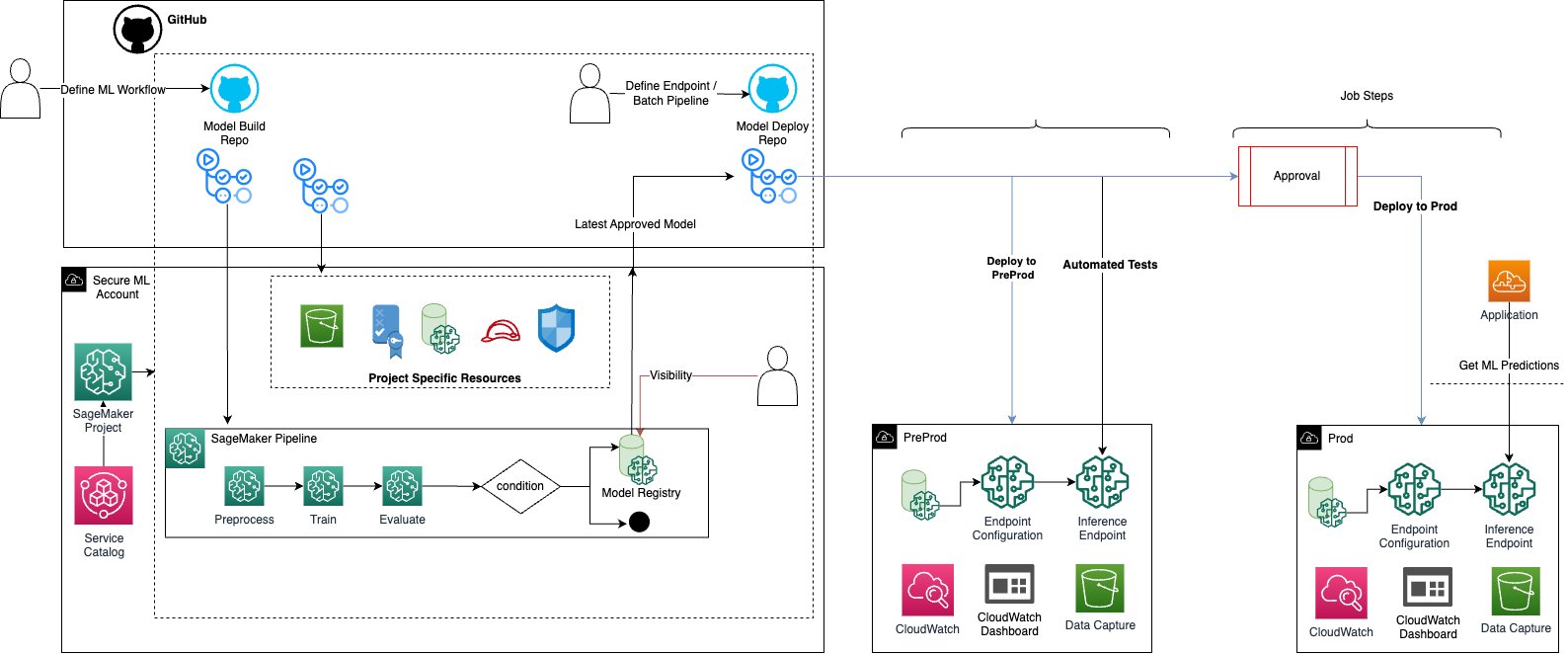
Implement a secure MLOps platform based on Terrafo...
Machine learning operations (MLOps) is the combination of people, processes, and technology to productionize ML use cases efficiently. To achieve this, enterprise customers must develop MLOps platforms to support reproducibility, robustness, and end-to-end observability of the ML use case’s...
1 week ago
4
Automate Amazon QuickSight data stories creation w...
In this post, we demonstrate how Amazon Nova Act automates QuickSight data story creation, saving time so you can focus on making critical, data-driven business decisions.
1 week ago
3
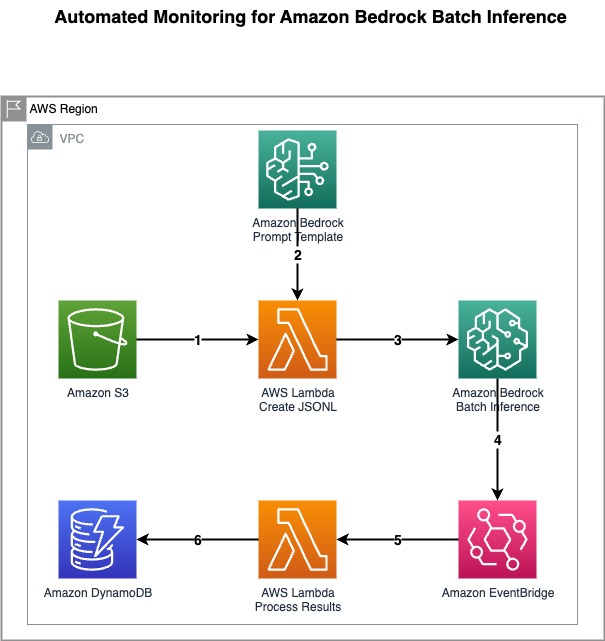
Implement automated monitoring for Amazon Bedrock ...
In this post, we demonstrated how a financial services company can use an FM to process large volumes of customer records and get specific data-driven product recommendations. We also showed how to implement an automated monitoring solution for Amazon...
1 week ago
5

Responsible AI: How PowerSchool safeguards million...
In this post, we demonstrate how PowerSchool built and deployed a custom content filtering solution using Amazon SageMaker AI that achieved better accuracy while maintaining low false positive rates. We walk through our technical approach to fine tuning Llama...
1 week ago
2
Unlock global AI inference scalability using new g...
Organizations are increasingly integrating generative AI capabilities into their applications to enhance customer experiences, streamline operations, and drive innovation. As generative AI workloads continue to grow in scale and importance, organizations face new challenges in maintaining consistent performance, reliability,...
2 weeks ago
9
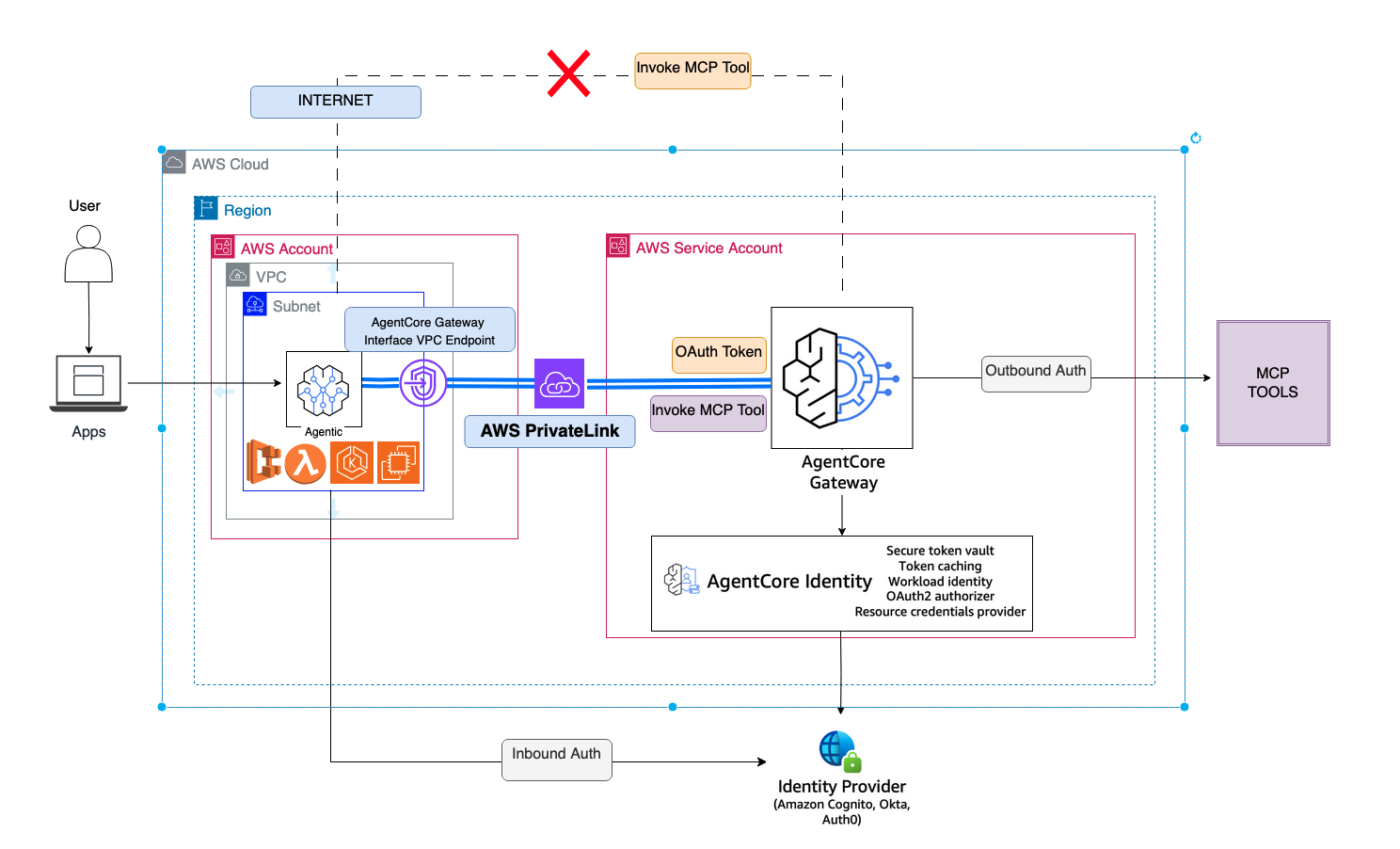
Secure ingress connectivity to Amazon Bedrock Agen...
In this post, we demonstrate how to access AgentCore Gateway through a VPC interface endpoint from an Amazon Elastic Compute Cloud (Amazon EC2) instance in a VPC. We also show how to configure your VPC endpoint policy to provide...
2 weeks ago
7
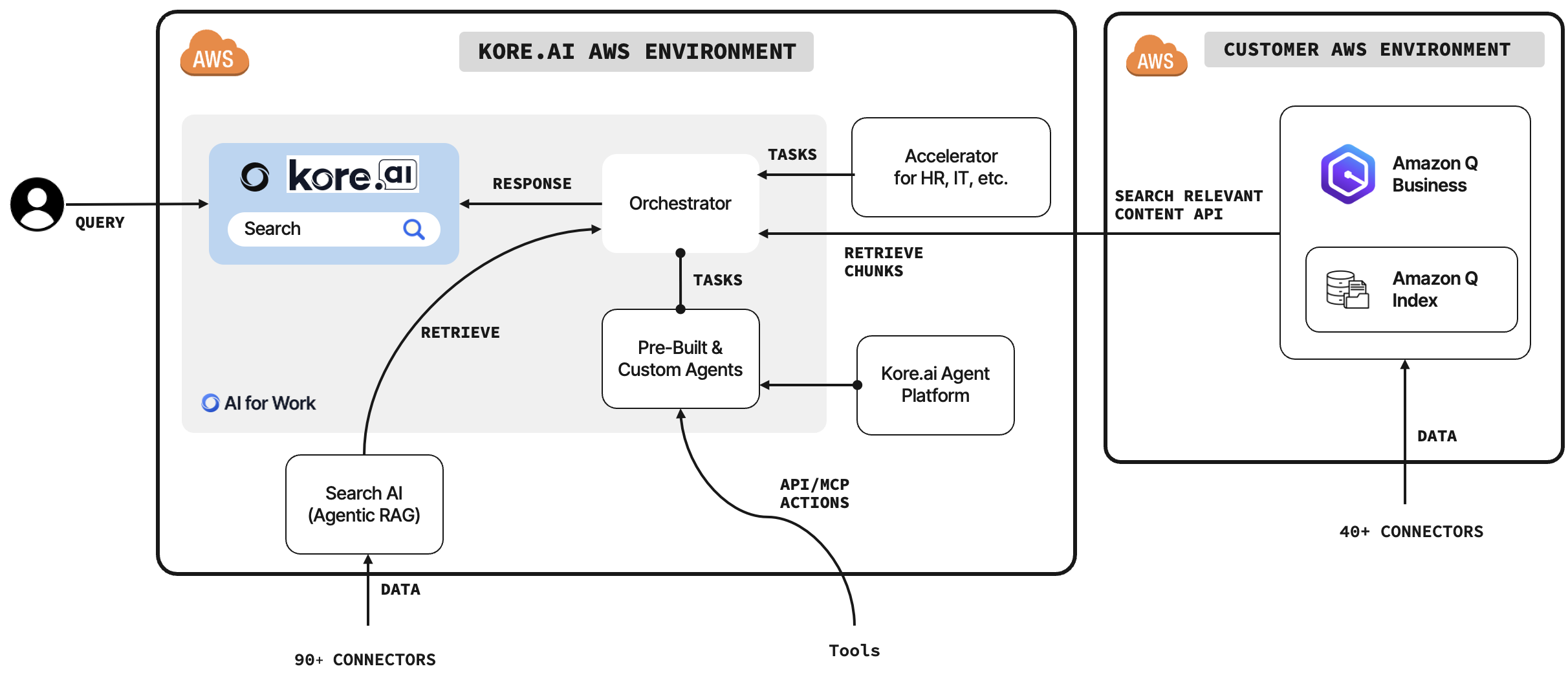
Enhance agentic workflows with enterprise search u...
In this post, we demonstrate how organizations can enhance their employee productivity by integrating Kore.ai’s AI for Work platform with Amazon Q Business. We show how to configure AI for Work as a data accessor for Amazon Q index...
2 weeks ago
10
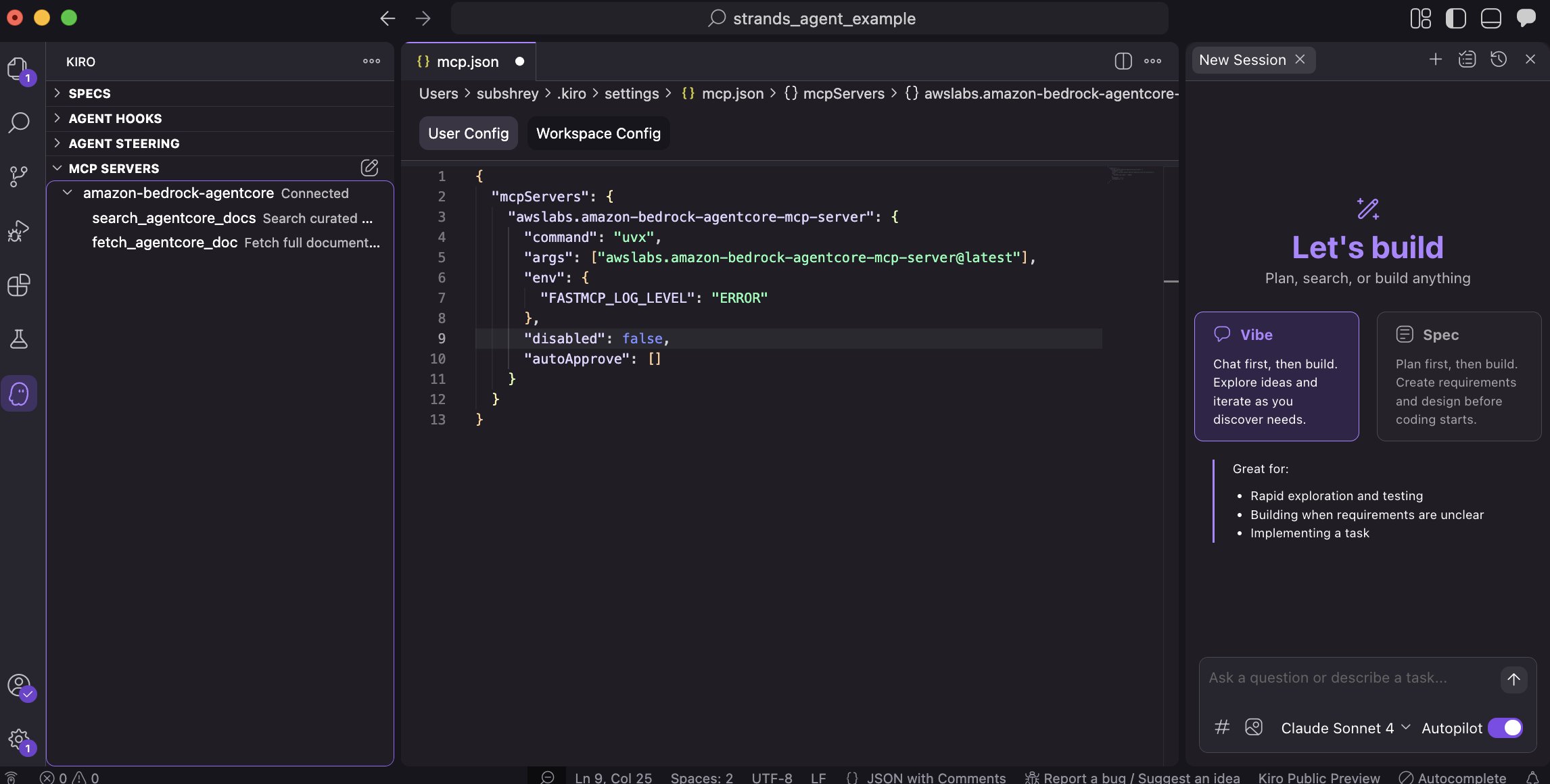
Accelerate development with the Amazon Bedrock Age...
Today, we’re excited to announce the Amazon Bedrock AgentCore Model Context Protocol (MCP) Server. With built-in support for runtime, gateway integration, identity management, and agent memory, the AgentCore MCP Server is purpose-built to speed up creation of components compatible...
2 weeks ago
7
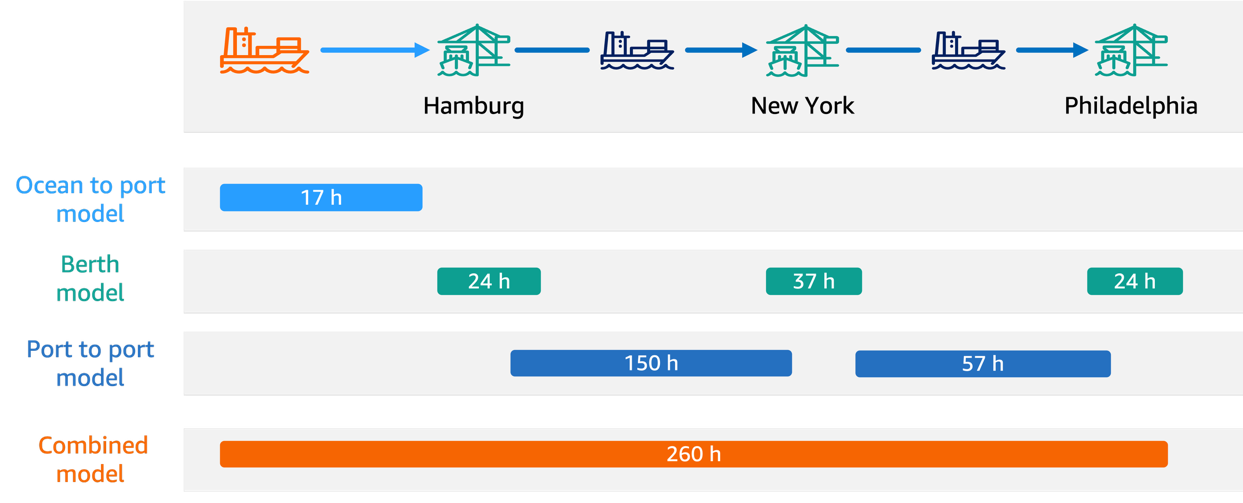
How Hapag-Lloyd improved schedule reliability with...
In this post, we share how Hapag-Lloyd developed and implemented a machine learning (ML)-powered assistant predicting vessel arrival and departure times that revolutionizes their schedule planning. By using Amazon SageMaker AI and implementing robust MLOps practices, Hapag-Lloyd has enhanced...
2 weeks ago
7
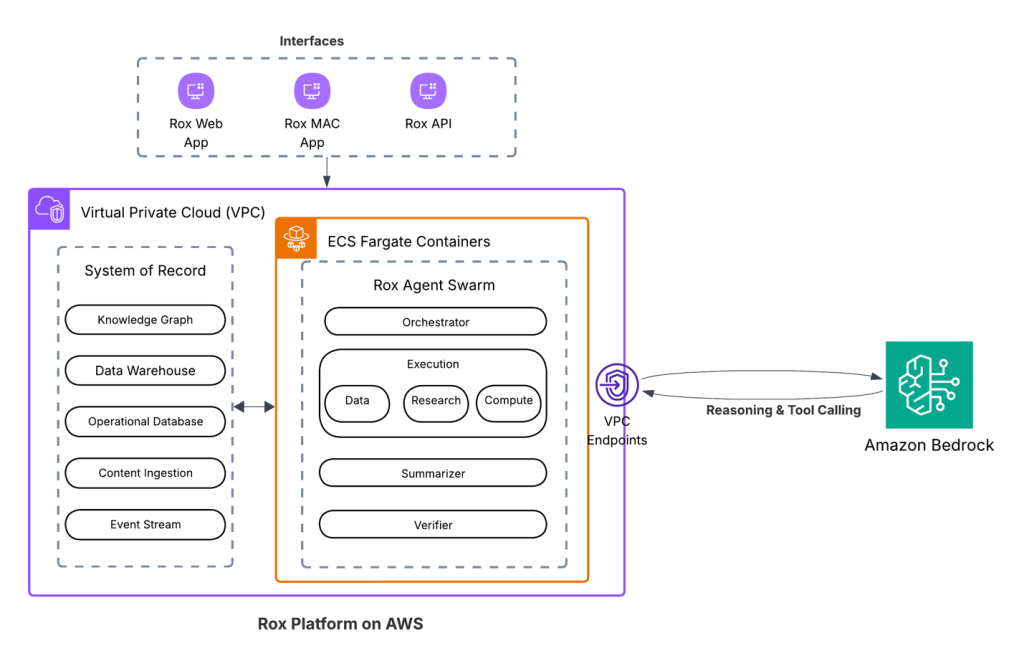
Rox accelerates sales productivity with AI agents ...
We’re excited to announce that Rox is generally available, with Rox infrastructure built on AWS and delivered across web, Slack, macOS, and iOS. In this post, we share how Rox accelerates sales productivity with AI agents powered by Amazon...
2 weeks ago
8
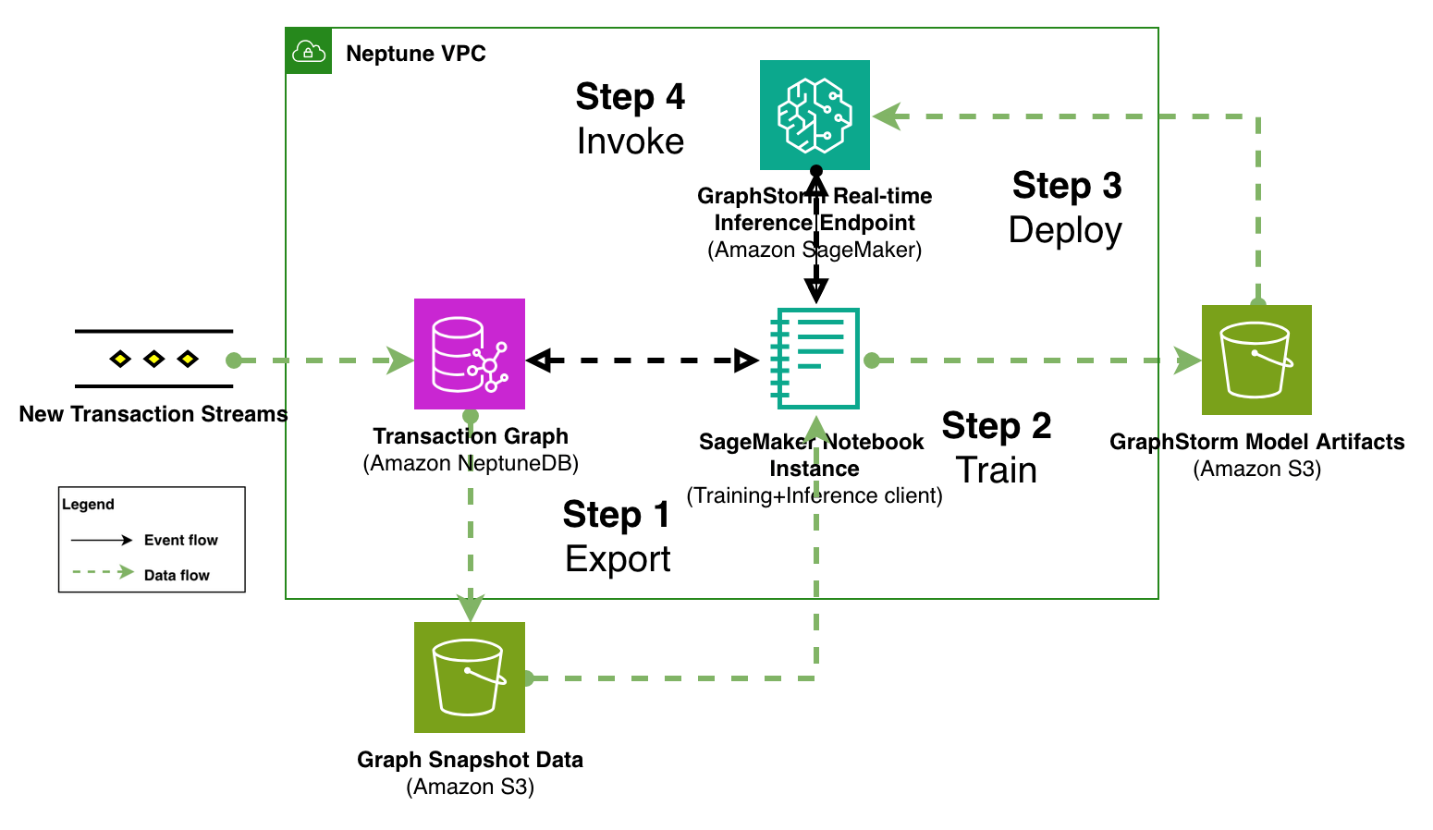
Modernize fraud prevention: GraphStorm v0.5 for re...
In this post, we demonstrate how to implement real-time fraud prevention using GraphStorm v0.5's new capabilities for deploying graph neural network (GNN) models through Amazon SageMaker. We show how to transition from model training to production-ready inference endpoints with...
2 weeks ago
12









 English (US) ·
English (US) ·